

0 引言
协同目标分配, 决定了兵力运用的科学性和合理性, 是将作战意图落地为作战行动的关键环节[1]。在同一时间或空间范围内, 多个作战单元为完成同一项作战任务或相互之间存在逻辑关系的多个作战任务时, 需从时间、空间和效果等角度考虑, 进行目标或火力的合理分配, 以最大作战效费比和最小作战风险获得最优打击效果。
协同目标分配是一种典型的非线性多项式完全问题, 决策空间随问题规模(即作战单元数目和作战目标数目)增大呈指数级增长, 求解结果的的实时性、准确性和有效性将直接影响军事对抗中能否取得最佳作战效果。在军事运筹领域, 协同目标分配通常被规约为兵力分配、火力分配或武器目标分配(weapon target assignment, WTA)等问题[2-3], 常用求解方法可分为传统规划方法[4]、模拟退火(simulated annealing, SA)算法[5-6]、蚁群优化(ant colony optimization, ACO)算法[7]、粒子群优化(partical swarm optimization, PSO)算法[8-11]、进化算法(evolutionary algorithm, EA)[12-15]和合同网协议(contract net protocol, CNP)[16]。现有研究虽从不同角度对各种算法进行了改进, 并成功应用于不同场景, 但关于动态不确定环境下的协同目标分配研究较少, 且难以保证大规模目标分配问题的求解效率。
在分布式作战自同步理论中[17], 协同关系体现为作战单元“自底向上组织复杂战争的行为”。将作战单元构建为智能体, 协同目标分配问题便转化为多智能体协作(multi-agent cooperation, MAC)问题, 多智能体强化学习(multi-agent reinforcement learning, MARL)[18]在解决类似协作问题上有着广泛应用[19-23]。据此, 通过分析协同目标分配的军事内涵, 构建了基于MARL的协同目标分配模型, 采用局部策略评分和集中式策略推理, 利用Advantage Actor-Critic算法进行策略学习, 以期能够实现简单场景中训练好的模型直接泛化应用到复杂场景, 从而有效实现大规模目标分配。
1 协同目标分配数学模型
1.1 相关概念
为在统一语义框架下描述协同目标分配问题, 定义以下相关概念。
作战单元, 指能够独立遂行作战任务的基本作战单位, 为执行作战任务提供作战资源。在协同目标分配中, 作战单元是不可再分割的基本作战单位或作战平台。
作战目标, 指战场上存在且具有一定军事价值的客观实体, 是作战单元执行作战任务时所作用的客观对象。
作战协同关系, 指多个作战单元在同一时空范围内执行同一作战任务或具有逻辑关系的不同作战任务时, 在空间部署、时间衔接、目标分配、火力分配和效果达成等方面, 所形成的相互照应、相互配合和优劣互补的关系。
1.2 符号定义
协同目标分配描述过程中, 定义以下符号。
(1) Tg={tg1, tg2, …, tgN}: 打击目标清单列表, N为打击目标总数。
(2) U={u1, u2, …, uM}: 进攻方可用作战单元列表, M为作战单元总数。
(3) W={w1, w2, …, wL}: 进攻方可用弹药类型列表, L为弹药类型总数。
(4) Vtg={vtg1, vtg2, …, vtgN}: 各作战目标被摧毁后的收益价值列表。vtgi为打击目标tgi被摧毁后的收益价值, i∈{1, 2, …, N}。
(5) Vu={vu1, vu2, …, vuM}: 各作战单元被摧毁后的损失价值列表。vuj为作战单元uj被摧毁后的损失价值, j∈{1, 2, …, M}。
(6) Vw={vw1, vw2, …, vwL}: 各类型弹药消耗单位数量后的损失价值列表。vwl为wl类型弹药消耗单位数量后的损失价值, l∈{1, 2, …, L}。
(7) Tglt=(tglt, 1, tglt, 2, …, tglt, N): 执行第t次分配方案时被摧毁目标清单。tglt, i表示目标tgi是否被摧毁, tglt, i=1表示被摧毁, 否则tglt, i=0。
(8) Ult=(ult, 1, ult, 2, …, ult, M): 执行第t次目标分配方案时被摧毁单元清单。ult, j表示单元uj是否被摧毁, ult, j=1表示被摧毁, 否则ult, j=0。
(9) Wlt=(wlt, 1, wlt, 2, …, wlt, L): 执行第t次目标分配方案时进攻方的弹药消耗清单。wlt, l表示wl类型弹药的消耗数量。
(10) Vlsumt: 执行第t次目标分配方案时防守方的弹药消耗价值总量。
(11) Wut, j=(wt, j, 1, wt, j, 2, …, wt, j, L): 执行第t次目标分配方案时进攻方作战单元uj的挂载。wj, l为作战单元uj挂载的wl类型弹药的数目。
(12) RPro=[rprol, i]L×N: 进攻方各类弹药对不同作战目标的命中毁伤概率矩阵。rprol, i为wl类型弹药对作战目标tgi的命中毁伤概率。
(13) BPro=(bpro1, bpro2, …, bproM): 防守方一体化联合防空反导对进攻方各作战单元的综合命中毁伤概率矩阵。bproj为对作战单元uj的综合命中毁伤概率。
1.3 数学模型
考虑使命任务、弹目匹配以及作战效费比等因素建立数学模型, 如下所示:
(1) 模型变量
令变量xi, j, t表示在第t次作战目标分配时, 是否指派作战单元uj打击作战目标tgi。当指派单元uj打击目标tgi时, xi, j, t=1, 否则xi, j, t=0。因此, 模型变量为
式中: T为作战过程中进行目标分配的总次数; 模型变量规模为N×M×T, 在相同问题背景下, 随着决策次数T的增大呈线性增长。
(2) 目标函数
模型目标函数, 衡量了作战效果的大小。参数α和β, 用于平衡两部分计算结果对目标函数值的影响;F1(X)表示任务使命完成度, 计算方法如下所示:
式中: Rle和Ble分别表示作战结束后作战单元和作战目标的剩余率。
F2(X)/F3(X)表示作战效费比; F2(X)表示作战过程中摧毁敌方作战目标和消耗敌方弹药所产生的总收益; F3(X)表示作战过程中自身作战单元被摧毁和弹药消耗所产生的总损失, 计算方法如下所示:
(3) 约束条件
1) Φ(t)表示执行第t次目标分配方案所产生的结果。根据各方弹目匹配关系及命中毁伤概率(BPro与RPro), 执行作战目标分配方案Xt, 得到进攻方作战单元损失情况Ult和弹药消耗情况Wlt、敌方作战目标被摧毁情况Tglt和弹药消耗总价值Vlsumt。
2)
3)
4)
5)
6)
2 协同目标分配求解方法
协同目标分配, 可表示为MDP(S1, S2, A, R, P, m, n, π), m和n分别表示作战单元和作战目标的数目; S1是所有作战目标的联合状态空间, S1i(i∈{1, 2, …, m})是第i个作战目标的状态集; S2和A是所有作战单元的联合状态空间和联合动作空间, S2j和Aj(j∈{1, 2, …, n})是第j个作战单元的状态集和动作集; R: S1×S2×A→ R为奖励函数; P: S1×S2×A×S1×S2→[0, 1]为状态转移概率; π: S1×S2→A为一个确定的联合策略。
考虑远期决策对当前收益影响的衰减, 动作价值函数如下所示:
式中: St为时刻t作战单元和作战目标的联合状态; E(·)为求解期望值的函数。
问题目标是通过学习获取一个最优协同目标分配策略, 保证所有作战单元的协同打击行动能够使奖励函数在长期内达到最大化, 如下所示:
2.1 模型训练及应用框架
在此, 构建基于MARL的协同目标分配模型训练及应用框架, 如图 1所示, 具体流程如下。
图1
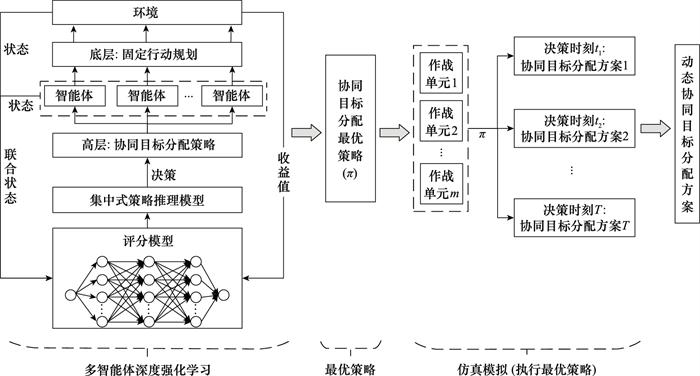
图1
基于MARL的协同目标分配模型训练与应用
Fig.1
Training and application of cooperative targets assignment model based on MARL
步骤1 基于深度强化学习优化协同目标分配策略。在此, “智能体”是进攻方的各作战单元, “动作”是作战单元选择打击哪个作战目标, “环境”是本文实验平台-计算机兵棋推演系统的模拟仿真环境, “状态”为所有作战单元和作战目标的联合状态。在每一步学习中, 采用“集中式策略推理模型”获取目标分配方案, 各作战单元根据分配方案和固定行动规则对作战目标进行打击, 兵棋系统会实时返回各棋子状态和交战结果。而后, 依据系统环境返回的收益值信息, 利用基于多层神经网络的“评分模型”对该步目标分配方案进行优劣评价, 评价值用于优化策略。
步骤2 最优协同目标分配策略的模拟执行。在利用计算机兵棋系统对某次联合火力打击进行模拟仿真时, 每隔一段时间Δt, 依据最优协同目标分配策略生成目标分配方案, 各作战单元依据当前方案实时调整打击对象。当完成打击任务后, 将得到一个随时间变化的“作战目标分配方案序列”。
作战单元在各目标分配方案中分配得到的作战目标, 组成了该作战单元的打击目标序列; 作战目标在各目标分配方案中是否被打击, 形成了不同作战目标之间的先后打击顺序。
2.1.1 协同目标分配方案表示
在决策时刻t, 一个确定的策略π会根据所有作战单元和作战目标的联合状态〈S1, t, S2, t〉, 给出能够获取最大回报的联合动作At=max π(S1, t, S2, t, t)。At实质就是时刻t的协同目标分配方案, 可用分配矩阵Bt等价表示, 如下所示:
式中: bi, j表示作战单元uj是否打击作战目标tgi, 如果打击则bi, j=1, 否则bi, j=0。
若每隔时间Δt生成一次作战目标分配方案, 当完成打击任务后, 将会得到该作战场景下的一个作战目标分配方案序列, 如下所示:
2.1.2 底层固定行动规则
当给定分配矩阵Bt后, 各作战单元将会按照固定行动规则对指派的作战目标进行打击。作战单元的行动规则包括: 作战单元自动规划打击目标的最短路径; 作战目标进入射程范围后, 作战单元将根据自身挂载的命中毁伤概率, 计算弹药发射数量; 作战单元消耗完自身弹药或油料后将自动退出作战。上述行动规划均由计算机兵棋系统自动完成, 符合军事规范并在长期应用中得到验证。因此, 学习任务将聚焦于分配策略π的学习, 而作战单元对作战目标的具体打击行为不需要进行训练。
2.1.3 奖励函数
根据协同目标分配模型的目标函数, 构建强化学习的单步奖励函数, 计算方法如下所示:
式中: Rt表示在第t步得到的单步奖励值; bvs和blst表示防守方作战目标及弹药的总价值与第t步时被摧毁/消耗后的总收益; rvs和rlst表示进攻方作战单元及弹药的总价值与第t步时被摧毁/消耗后的总损失; d标识作战过程是否结束, 若结束则d=1, 否则d=0;r_d为作战结束时的奖励值; Rle和Ble分别表示作战过程结束后作战单元和作战目标的剩余率。
2.2 协同策略评分模型
评分模型根据作战单元和作战目标的状态,评价当前策略的优劣。在此,采用多层神经网络构建局部评分模型,通过不断学习优化模型参数来提高模型评分的精确度,可用h(s1, i, s2, j, θ1)和g(s1, i, s1, k, θ2)表示。其中,h(·)对作战单元与作战目标的分配关系进行评分, 反映了指派作战单元uj打击作战目标tgi的优劣; g(·)对作战目标之间的打击顺序进行评分, 反映了作战目标tgi与tgk先后打击顺序的优劣; s2, j表示作战单元uj的状态; s1, i和s1, k分别表示作战目标tgi与tgk的状态; θ1和θ2分别为两个神经网络的参数。
在某一决策时刻, 经过评分后可得到两个评分矩阵H和G, 分别如下所示:
式中: hθ1(i, j)表示对作战单元uj打击作战目标tgi的评分; gθ2(i, k)表示对作战目标tgi与tgk打击顺序的评分。
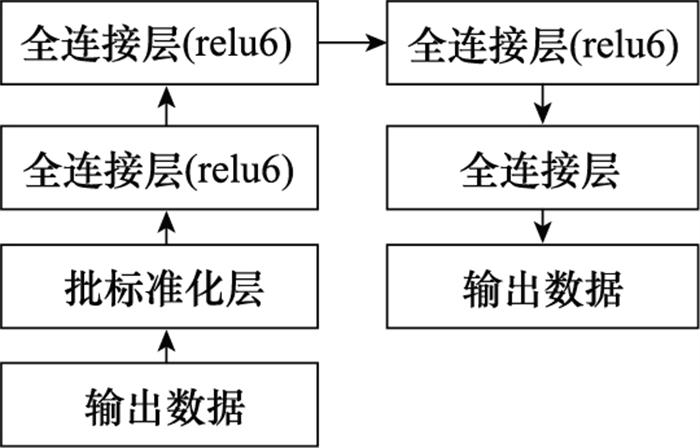
评分模型h(·)和g(·)分别采用结构相同但参数不同的神经网络, 如图 2所示。h(·)的输入数据为评分对象“作战单元和作战目标”的联合状态向量; g(·)的输入数据为评分对象“作战目标和作战目标”的联合状态向量。作战单元和作战目标的特征状态, 包括类型、位置、自身价值、弹药携带量和弹药单位价值。输入数据经过批标准化层和4个全连接层后, 输出评分数值。
图2
2.3 协同策略推理模型
协同策略推理模型主要负责根据评分矩阵H和G确定能够获取最大评分总数的分配矩阵Bt。在协同目标分配策略π为确定性策略时, 分配矩阵Bt只与当前t时刻各作战单元和作战目标的联合状态有关。在学习过程中, 分配矩阵Bt还取决于评分模型的网络参数θ1和θ2。因此, 可使用参数化Bt(S1, S2, θ1, θ2)表示分配矩阵。
一种贪婪的策略推理, 是将作战单元指派给h(·)分数最高的作战目标。但贪婪地选择分数最大的作战单元打击作战目标, 实质是默认打击目标的效益与指派打击该目标的作战单元数目呈正比例关系。然而, 当作战单元和作战目标数目较多时, 打击某一作战目标的总收益, 会随着指派作战单元的数目增大而趋于饱和, 从而导致严重的资源浪费。因此, 需要限制打击同一作战目标的作战单元数量。
此外, 还需要考虑不同作战目标的先后打击顺序。当考虑作战目标之间的约束关系时, 可能会出现两种极端情况: 一种情况是作战目标之间的相关关系较弱, 则作战单元会被“分散”指派给各个作战目标并同时执行打击任务; 另一种情况是作战目标之间存在较强的相关关系, 则作战单元会被“集中”指派去打击重要性较大的作战目标, 而后按照重要性顺序依次打击其他作战目标。在实际作战中, 作战目标之间的重要性对比关系, 应处于上述两种极端情况之间。
协同策略推理过程, 可表示为
式中, bi, j为分配矩阵Bt(S1, S2, θ1, θ2)中第i行第j列的元素, 表示作战单元uj是否打击作战目标tgi; h(i, j, θ1) 为评分矩阵H中第i行第j列的元素, 表示指派作战单元uj打击作战目标tgi的优劣程度; g(i, k, θ2)为评分矩阵G中第i行第k列的元素, 表示对作战目标tgi与tgk的打击顺序的评分; 约束条件
2.4 协同策略学习算法
图3

步骤1 策略网络Actor为第2.2节中所构建的评分模型。神经网络接收当前作战单元和作战目标的空间分布状态, 通过网络前向传播计算评分矩阵H和G。然后, 将H和G作为“动作”输出给协同策略推理模型。
步骤2 协同策略推理模型根据评分矩阵H和G, 通过策略推理制定协同目标分配方案, 具体方法如第2.3节所述。然后, 将协同目标分配方案下达给各作战单元, 各作战单元按照底层固定的行动策略执行目标打击任务。
步骤3 评价网络Critic接收目标分配方案单步执行后产生的奖励值, 单步奖励值的计算方法如式(11)所示。然后, 通过神经网络的前向传播计算执行“动作”H和G所产生的评价值, 并更新优化网络参数。最后, 将计算得到的关于收益的TD-error输出给策略网络Actor。
步骤4 策略网络Actor接收TD-error后, 更新优化评分模型的网络参数θ1和θ2。
步骤5 迭代上述过程, 直至学习结束。
3 实验验证
在某型计算机兵棋系统上, 以联合火力打击为例, 验证本文协同目标分配方法。
(1) 实验设计与数据
实验背景: 为保证联合任务部队能够顺利渡海登陆, 现对敌沿岸雷达阵地、防空阵地、机场和指挥所进行联合火力打击。
表1 武器平台和作战目标信息
Table 1
| 类型 | 平台价值系数 | 挂载类型 | 数量 | 弹药 | |||
| 小场景 | 大场景 | 数量 | 价值系数 | ||||
| 常导 | 0.6 | W1 | 2 | 8 | - | - | |
| 歼轰机1 | 0.4 | W2 | 3 | 4 | 4 | 0.05 | |
| 歼轰机2 | 0.5 | W2 | 3 | 4 | 4 | 0.05 | |
| 轰炸机 | 0.6 | W3 | 2 | 3 | 8 | 0.05 | |
| 雷达 | 0.5 | - | 2 | 4 | - | - | |
| 导弹发射架 | 0.8 | - | 4 | 14 | - | - | |
| 机场跑道 | 0.6 | - | 1 | 2 | - | - | |
| 指挥所 | 0.9 | - | 1 | 2 | - | - | |
表2 武器-目标命中毁伤概率
Table 2
| 武器 | 目标 | |||||||
| 常导 | 歼轰机1 | 歼轰机2 | 轰炸机 | 雷达 | 防空阵地 | 机场跑道 | 指挥所 | |
| 常导 | - | - | - | - | 0.6 | 0.7 | 0 | 0.8 |
| 歼轰机1 | - | - | - | - | 0.8 | 0.7 | 0 | 0.6 |
| 歼轰机2 | - | - | - | - | 0.6 | 0.6 | 0.5 | 0.7 |
| 轰炸机 | - | - | - | - | 0.7 | 0 | 0.7 | 0.6 |
| 防空反导系统 | 0.4 | 0.4 | 0.4 | 0.5 | - | - | - | - |
(2) 小场景下模型训练与验证
由于“武器-目标”命中毁伤概率小于1, 即便训练得到的策略最优, 也会出现收益值很差的情况。在此, 将每一轮训练的总回报, 设置为本次训练总回报与前一轮训练总回报的综合值, 计算方法如下所示:
式中: G′n+1为第n+1次训练周期的综合回报值; G′n为第n次训练周期的综合回报值; Gn+1为第n+1次训练周期的原始回报值。
根据本文方法构建评分模型、推理模型和学习模型, 利用计算机兵棋系统进行1 050轮学习训练。训练过程中, 综合回报值随训练次数的变化曲线, 如图 4所示。可见, 基于A2C算法的策略优化方法能够保证策略回报值趋于收敛, 从而得到最优协同目标分配策略。
图4
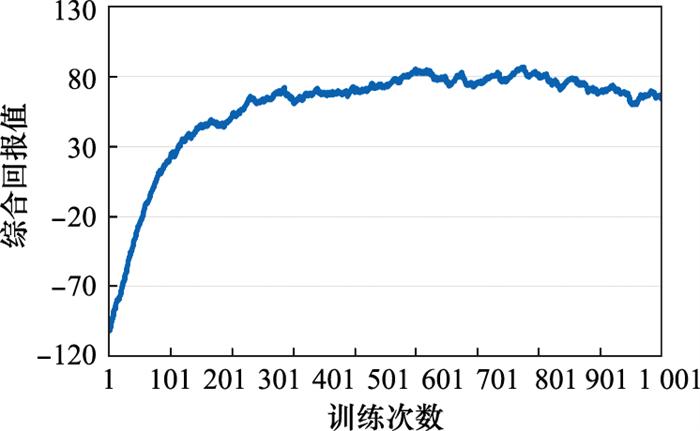
图5
(3) 大场景下模型泛化应用
在大场景下, 不进行任何学习训练, 直接使用小场景中训练好的模型和策略, 进行70次模拟仿真泛化应用验证, 统计信息如图 6所示。
图6
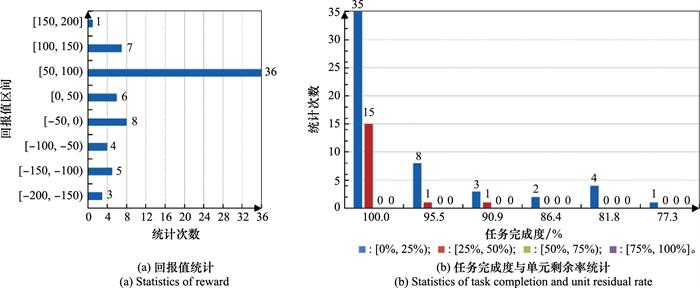
图6
大场景下模型泛化应用结果
Fig.6
Results of model generalization application in large scenes
(4) 实验结果分析
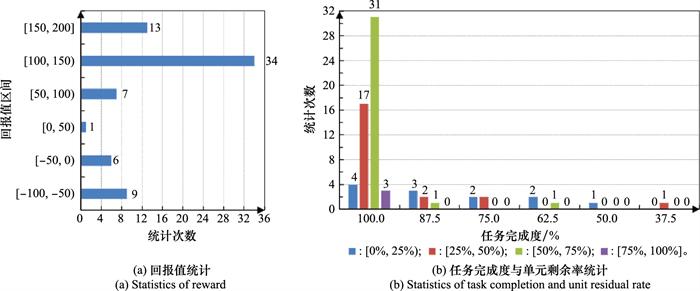
1) 在小场景验证实验中, 综合回报值落在区间[50, 200]的模拟次数占总次数的77%;能够百分之百完成打击任务的模拟次数占总次数的78.6%, 而能够保证自身损失不超过50%的模拟次数占总次数的48.6%。虽然存在我方损失很大而敌方损失较小的情况, 但非协同分配策略导致, 而是由于敌我双方命中毁伤概率小于1产生的小概率随机结果。因此, 训练优化的策略能够保证进攻方以较小损失完成联合火力打击任务。
2) 在大场景泛化应用实验中, 综合回报值落在区间[50, 200]的模拟次数占总次数的62.9%;能够百分之百完成打击任务的模拟次数占总次数的71.4%。相比小场景实验, 进攻方的作战单元损失较大且收益平均值较小。主要原因是大场景下作战目标是小场景的2.75倍, 而武器平台只是小场景的1.9倍, 因此进攻方会产生更大的损失。但训练优化的策略, 依旧能够保证进攻方以较大概率完成联合火力打击任务。
4 结论
本文针对传统方法难以实现动态不确定环境下的大规模协同目标分配问题, 提出了基于MARL的协同目标分配方法。通过策略分层将学习任务聚焦于顶层分配策略的学习, 构建了策略评分模型和策略推理模型, 并基于A2C算法进行策略的优化学习。实验结果表明, 基于多智能体系统对作战单元协同作战行为进行建模, 能够形象地刻画协同作战的演化内因; 基于A2C算法的策略优化方法, 能够确保最优协同目标分配策略的有效生成; 而生成的最优目标分配策略, 能够在执行时以较好的效果完成联合火力打击任务。
参考文献
协同目标分配问题研究综述
[J].DOI:10.16182/j.issn1004731x.joss.19-FZ0382 [本文引用: 1]
Overview of cooperative target assignment
[J].DOI:10.16182/j.issn1004731x.joss.19-FZ0382 [本文引用: 1]
The weapon-target assignment problem
[J].DOI:10.1016/j.cor.2018.10.015 [本文引用: 1]
Real-time heuristic algorithms for the static weapon target assignment problem
[J].DOI:10.1007/s10732-018-9401-1 [本文引用: 1]
A parallel simulated annealing algorithm for weapon-target assignment problem
[J].
分布式遗传模拟退火算法的火力打击目标分配优化
[J].DOI:10.3969/j.issn.1002-0640.2016.03.022 [本文引用: 1]
Optimization for target assignment in fire strike based on distributed genetic simulated annealing algorithm
[J].DOI:10.3969/j.issn.1002-0640.2016.03.022 [本文引用: 1]
Weapon-target assignment based on simulated annealing and discrete particle swarm optimization in coope-rative air combat
[J].
Simplified swarm optimization with initialization scheme for dynamic weapon-target assignment problem
[J].DOI:10.1016/j.asoc.2019.105542
Solving the dynamic weapon target assignment problem by an improved artificial bee colony algorithm with heuristic factor initialization
[J].DOI:10.1016/j.asoc.2018.06.014 [本文引用: 1]
Advanced input generating algorithm for effect-based weapon-target pairing Optimization
[J].DOI:10.1109/TSMCA.2011.2159591
改进差分进化算法求解武器目标分配问题
[J].
Improved differential evolution algorithm for solving weapon-target assignment pro-blem
[J].
改进合同网协议在防空武器目标分配中的应用
[J].DOI:10.3969/j.issn.1009-086x.2017.04.017 [本文引用: 1]
Application of improved contract net protocol on weapon target assignment of air defense combat
[J].DOI:10.3969/j.issn.1009-086x.2017.04.017 [本文引用: 1]
A survey and critique of multiagent deep reinforcement learning
[J].DOI:10.1007/s10458-019-09421-1 [本文引用: 1]
Multi-agent deep reinforcement learning for large-scale traffic signal control
[J].
Actor-Critic框架下的多智能体决策方法及其在兵棋上的应用
[J].
Multi-agent decision-making method based on Actor-Critic framework and its application in wargame
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}