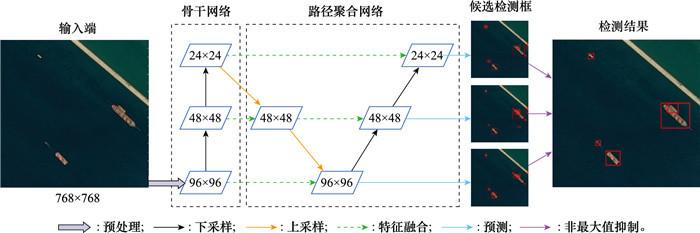
图1
YOLOv5s算法流程
Fig.1
YOLOv5s algorithm flow chart
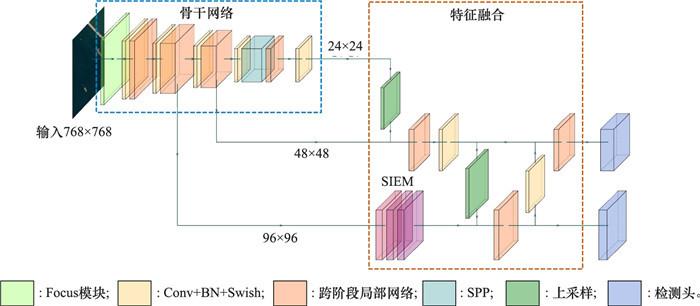
图2
改进的YOLOv5网络结构
Fig.2
Improved YOLOv5 network structure
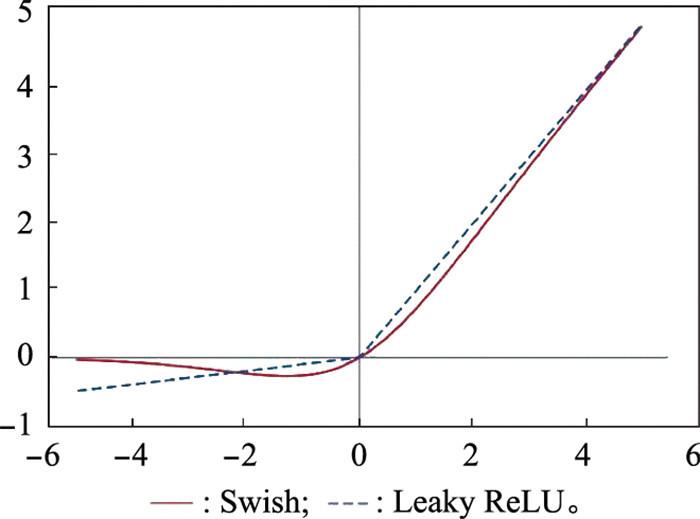
图3
Swish函数与Leaky ReLU函数曲线对比
Fig.3
Comparison of Swish and Leaky ReLU function
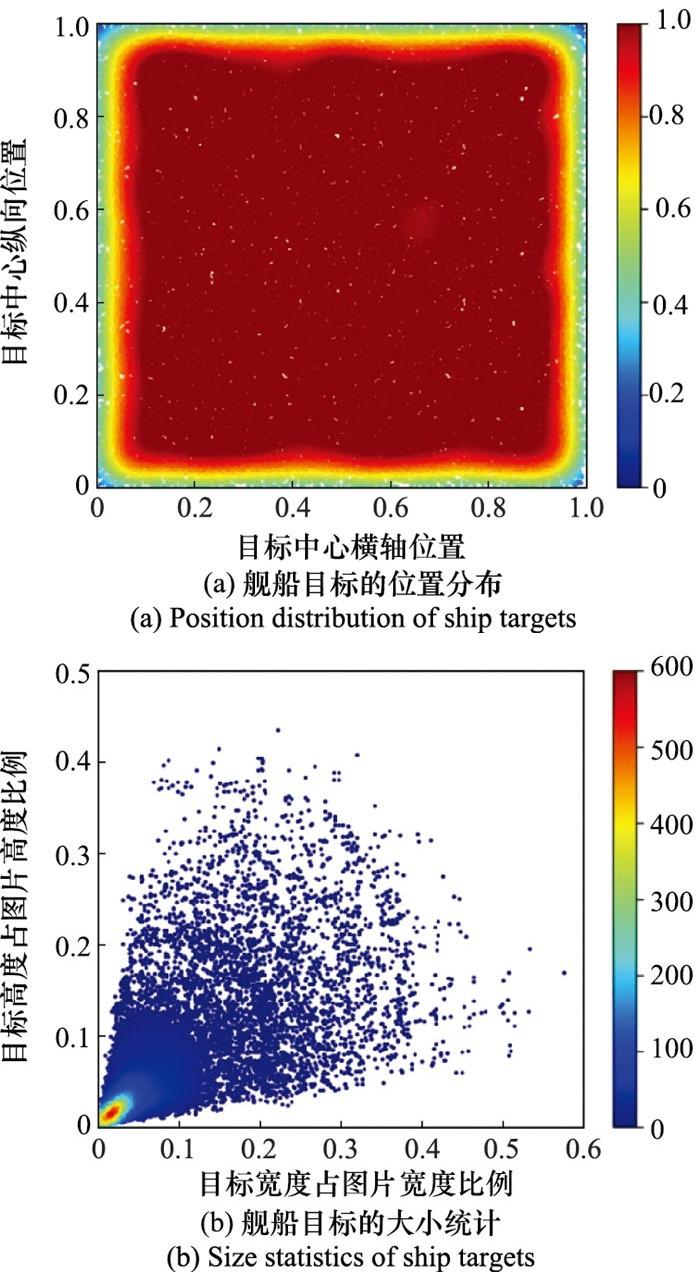
图4
数据集中舰船目标的位置分布和大小
Fig.4
Overview of ship target position and size in the dataset
为说明改进模型能够提取到更鲁棒的特征, 采用Grad-Cam++[30 ] 方法, 在模型的检测端对各检测头的特征图进行加权组合, 获得含有类别信息的显著图, 即类激活图。图 5 分别绘制了YOLOv5s原始模型检测端以及改进模型检测端的类激活图。通过比较可以看出, 原始模型的小目标检测头表现尚可, 能够标示出目标存在区域, 但对比度相对不够明显, 而中目标检测头和大目标检测头则对背景区域投入了较大关注, 相比之下改进模型的两个检测头上都将注意力更多集中于目标区域, 且较为突出, 有效地抑制了背景区域, 但也同时存在一些可能引起错误检测的背景信息未被完全过滤。从检测头的维度进行比较可以看出, 主要针对大目标的检测头对于较小的舰船目标的检测贡献较少, 更多将注意力投向了背景区域。图 6 展示了改进模型在误检及漏检问题上相较于原始模型的改善, 分别选取两张图像说明改进模型在舰船目标大小差异大、目标间位置关系复杂等情况下的检测效果。图 6(a) 反映了改进模型对原始模型漏检情况的改善, 对于尺寸较小但航迹明显的目标和大目标旁紧邻的小目标取得了更好的检测效果, 说明改进模型确实能够提取到更具鲁棒性的特征以进行目标判别。图 6(b) 反映了改进模型在检测准确率上的改善, 相较于原始模型将没有停靠船舶的码头和靠近图片边缘的云雾识别为船只, 改进模型采取了更为严格的判别标准, 减少了误检情况的出现, 取得了更好的检测效果。
图5
类激活图对比
Fig.5
Comparison of class activation maps
图6
检测效果可视结果对比
Fig.6
Visual result comparison of detection effect
[1]
DONG Z , LIN B J . Learning a robust CNN-based rotation insensitive model for ship detection in VHR remote sensing ima-ges
[J]. International Journal of Remote Sensing , 2020 , 41 (9 ): 3614 - 3626 .
DOI:10.1080/01431161.2019.1706781
[本文引用: 1]
[2]
ZHU C R , ZHOU H , WANG R S , et al . A novel hierarchical method of ship detection from spaceborne optical image based on shape and texture features
[J]. IEEE Trans.on Geoscience and Remote Sensing , 2010 , 48 (9 ): 3446 - 3456 .
DOI:10.1109/TGRS.2010.2046330
[本文引用: 1]
[3]
董超. 可见光遥感图像海面舰船目标检测技术研究[D]. 长春: 中国科学院长春光学精密机械与物理研究所, 2020.
DONG C. Research on the detection of ship targets on the sea surface in optical remote sensing image[D]. Changchun: Changchun Institute of Optics, Fine Mechanics and Physics, Chinese Academy of Sciences, 2020.
[4]
王保云 , 张荣 , 袁圆 , 等 . 可见光遥感图像中舰船目标检测的多阶阈值分割方法
[J]. 中国科学技术大学学报 , 2011 , 41 (4 ): 293 - 298 .
URL
WANG B Y , ZHANG R , YUAN Y , et al . A new multi-level threshold segmentation method for ship targets detection in optical remote sensing images
[J]. Journal of University of Science and Technology of China , 2011 , 41 (4 ): 293 - 298 .
URL
[5]
GAN L, LIU P, WANG L Z. Rotation sliding window of the HOG feature in remote sensing images for ship detection[C]//Proc. of the International Symposium on Computational Intelligence and Design, 2015: 401-404.
[本文引用: 1]
[6]
TAYARA H , CHONG K T . Object detection in very high-resolution aerial images using one-stage densely connected feature pyramid network
[J]. Sensors , 2018 , 18 (10 ): 3341 .
DOI:10.3390/s18103341
[本文引用: 1]
[7]
GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]//Proc. of the IEEE Computer Society Conference on Computer Vision & Pattern Recognition, 2014: 580-587.
[本文引用: 1]
[8]
GIRSHICK R. Fast R-CNN[C]//Proc. of the IEEE Computer Society Conference on Computer Vision & Pattern Recognition, 2015: 1440-1448.
[本文引用: 1]
[9]
REN S Q , HE K M , GIRSHICK R , et al . Faster R-CNN: towards real-time object detection with region proposal networks
[J]. IEEE Trans.on Pattern Analysis and Machine Intelligence , 2017 , 39 (6 ): 1137 - 1149 .
DOI:10.1109/TPAMI.2016.2577031
[本文引用: 1]
[10]
HE K M , GKIOXARI G , DOLLAR P , et al . Mask R-CNN
[J]. IEEE Trans.on Pattern Analysis and Machine Intelligence , 2020 , 42 (2 ): 386 - 397 .
DOI:10.1109/TPAMI.2018.2844175
[本文引用: 1]
[11]
HE K M , ZHANG X Y , REN S Q , et al . Spatial pyramid pooling in deep convolutional networks for visual recognition
[J]. IEEE Trans.on Pattern Analysis and Machine Intelligence , 2015 , 37 (9 ): 1904 - 1916 .
DOI:10.1109/TPAMI.2015.2389824
[本文引用: 1]
[12]
REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection[C]//Proc. of the IEEE Conference on Computer Vision and Pattern Recognition, 2016: 779-788.
[本文引用: 2]
[13]
REDMON J, FARHADI A. YOLO9000: better, faster, stronger[C]//Proc. of the IEEE Conference on Computer Vision and Pattern Recognition, 2017: 7263-7271.
[14]
REDMON J, FARHADI A. YOLOv3: an incremental improvement[EB/OL]. [2021-11-21]. http://arxiv.org/abs/1804.02767 .
[15]
BOCHKOVSKIY A, WANG C Y, LIAO H. YOLOv4: optimal speed and accuracy of object detection[EB/OL]. [2021-11-21]. https://arxiv.org/abs/2004.10934 .
[16]
JOCHER G, STOKEN A, CHAURASIA A, et al. YOLOv5[EB/OL]. [2021-11-21]. http://github.com/ultralytics/yolov5 .
[本文引用: 3]
[17]
LIU W, ANGUELOV D, ERHAN D, et al. SSD: single shot multibox detector[M]//LEIBE B, MATAS J, SEBE N, et al. Lecture Notes in Computer Science, 2016.
[本文引用: 1]
[18]
FU C Y, LIU W, RANGA A, et al. DSSD: deconvolutional single shot detector[EB/OL]. [2021-11-21]. https://arxiv.org/abs/1701.06659 .
[本文引用: 1]
[19]
XIAO D , SHAN F , LI Z , et al . A target detection model based on improved tiny-YOLOv3 under the environment of mining truck
[J]. IEEE Access , 2019 , 7 , 123757 - 123764 .
DOI:10.1109/ACCESS.2019.2928603
[本文引用: 1]
[20]
徐诚极 , 王晓峰 , 杨亚东 . Attention-YOLO: 引入注意力机制的YOLO检测算法
[J]. 计算机工程与应用 , 2019 , 55 (6 ): 13 - 23 .
URL
[本文引用: 1]
XU C J , WANG X F , YANG Y D . Attention-YOLO: YOLO detection algorithm that introduces attention mechanism
[J]. Compu-ter Engineering and Applications , 2019 , 55 (6 ): 13 - 23 .
URL
[本文引用: 1]
[21]
郭进祥 , 刘立波 , 徐峰 , 等 . 基于YOLOv3的机场场面飞机检测方法
[J]. 激光与光电子学进展 , 2019 , 56 (19 ): 111 - 119 .
URL
[本文引用: 1]
GUO J X , LIU L B , XU F , et al . Airport scene aircraft detection method based on YOLOv3
[J]. Laser & Optoelectronics Progress , 2019 , 56 (19 ): 111 - 119 .
URL
[本文引用: 1]
[22]
GE Z, LIU S T, WANG F, et al. YOLOX: exceeding yolo series in 2021[EB/OL]. [2022-5-1]. http://arxiv.org/abs/2107.08430 .
[本文引用: 2]
[23]
ZHANG S F, CHI C, YAO Y Q, et al. Bridging the gap between anchor-based and anchor-free detection via adaptive training sample selection[C]//Proc. of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020: 9756-9765.
[本文引用: 1]
[24]
WANG C Y, MARKLIAO H Y, WU Y H, et al. CSPNet: a new backbone that can enhance learning capability of CNN[C]//Proc. of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, 2020: 390-391.
[本文引用: 1]
[25]
LIU S, QI L, QIN H F, et al. Path aggregation network for instance segmentation[C]//Proc. of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018: 8759-8769.
[本文引用: 1]
[26]
BODLA N, SINGH B, CHELLAPPA R, et al. Soft-NMS-improving object detection with one line of code[C]//Proc. of the IEEE International Conference on Computer Vision, 2017: 5561-5569.
[本文引用: 1]
[27]
LIN T Y, DOLLAR P, GIRSHICK R, et al. Path aggregation network for instance segmentation[C]//Proc. of the IEEE Conference on Computer Vision and Pattern Recognition, 2017: 936-944.
[本文引用: 1]
[28]
PRAJIT R, BARRET Z, QUOC V, et al. Swish: a self-gated activation function[EB/OL]. [2021-11-21]. https://arxiv.org/abs/1710.05941v1 .
[本文引用: 1]
[29]
KAGGLE. Dataset for airbus ship detection challenge[EB/OL]. [2021-11-21]. https://www.kaggle.com/c/airbus-ship-detection/data , 2018.
[本文引用: 1]
[30]
CHATTOPADHYAY A, SARKAR A, HOWLADER P, et al. Grad-CAM++: improved visual explanations for deep convolutional networks[C]//Proc. of the IEEE Winter Conference on Applications of Computer Vision, 2018: 839-847.
[本文引用: 1]
Learning a robust CNN-based rotation insensitive model for ship detection in VHR remote sensing ima-ges
1
2020
... 光学遥感图像由于拍摄距离相对较远, 遥感图像中的舰船目标通常相对较小, 图像的信噪比相对较低, 因此能够获得的目标特征相对有限.此外,来自海面背景、云雾海浪噪声干扰、目标遮挡、目标朝向不定等因素的影响均使得遥感图像舰船目标的实时检测面临较大挑战[1 ] . ...
A novel hierarchical method of ship detection from spaceborne optical image based on shape and texture features
1
2010
... 相比于传统舰船检测与识别方法[2 -5 ] , 基于深度学习的舰船目标检测识别方法的非线性拟合能力更强, 更适应于真实复杂场景下的舰船目标检测和识别.以卷积神经网络(convolutional neural network,CNN)为框架的检测模型主要分为两阶段检测和一阶段检测[6 ] .两阶段检测模型主要有R(region)-CNN[7 ] 、Fast R-CNN[8 ] 、Faster R-CNN[9 ] 、Mask R-CNN[10 ] 、空间金字塔池化网络(spatial pyramid pooling net,SPP-Net)[11 ] 等,其首先产生候选区域,然后再对该区域分类识别,具有较高的检测精度,但速度较慢,难以满足舰船目标检测应用中对实时性的要求.而以YOLO(you only look once)[12 -16 ] 、SSD(single shot multibox detector)[17 ] 、DSSD(deconvolutional SSD)[18 ] 等模型为代表的一阶段检测算法不需要区域候选阶段, 直接对目标的位置和类别进行回归, 虽检测精度相对较低, 但可达到更快的计算速度, 适合实时性较高的检测需求.为了提升YOLO的检测性能, 文献[19 ]基于tiny-YOLOv3增加了更多的卷积层以提高模型的特征提取能力, 并采用1×1的卷积核来降低特征的维度, 有效减少了训练和推理过程中的计算量.文献[20 ]将通道和空间注意力机制引入YOLO网络, 提高了舰船检测精度.文献[21 ]将骨干网络中的卷积层替换为空洞卷积来获取较大感受野, 并优化非极大值抑制算法, 提升模型检测准确率.2021年旷视科技发布了最新一代YOLO系列目标检测器YOLOX[22 ] , 以YOLOv3-SPP为基础改进, 采用了无锚框、解耦头、领先的标签分配策略、无非极大值抑制[23 ] 等技术, 相比YOLOv3, 提高了3%的检测精度, 并且提供了多种可选配的网络结构.众多文献基于YOLO系列算法实现了遥感图像中的实时目标检测, 但也在不同程度上面临小目标检测不敏感问题, 存在误检率或漏检率较高的情况. ...
可见光遥感图像中舰船目标检测的多阶阈值分割方法
0
2011
A new multi-level threshold segmentation method for ship targets detection in optical remote sensing images
0
2011
1
... 相比于传统舰船检测与识别方法[2 -5 ] , 基于深度学习的舰船目标检测识别方法的非线性拟合能力更强, 更适应于真实复杂场景下的舰船目标检测和识别.以卷积神经网络(convolutional neural network,CNN)为框架的检测模型主要分为两阶段检测和一阶段检测[6 ] .两阶段检测模型主要有R(region)-CNN[7 ] 、Fast R-CNN[8 ] 、Faster R-CNN[9 ] 、Mask R-CNN[10 ] 、空间金字塔池化网络(spatial pyramid pooling net,SPP-Net)[11 ] 等,其首先产生候选区域,然后再对该区域分类识别,具有较高的检测精度,但速度较慢,难以满足舰船目标检测应用中对实时性的要求.而以YOLO(you only look once)[12 -16 ] 、SSD(single shot multibox detector)[17 ] 、DSSD(deconvolutional SSD)[18 ] 等模型为代表的一阶段检测算法不需要区域候选阶段, 直接对目标的位置和类别进行回归, 虽检测精度相对较低, 但可达到更快的计算速度, 适合实时性较高的检测需求.为了提升YOLO的检测性能, 文献[19 ]基于tiny-YOLOv3增加了更多的卷积层以提高模型的特征提取能力, 并采用1×1的卷积核来降低特征的维度, 有效减少了训练和推理过程中的计算量.文献[20 ]将通道和空间注意力机制引入YOLO网络, 提高了舰船检测精度.文献[21 ]将骨干网络中的卷积层替换为空洞卷积来获取较大感受野, 并优化非极大值抑制算法, 提升模型检测准确率.2021年旷视科技发布了最新一代YOLO系列目标检测器YOLOX[22 ] , 以YOLOv3-SPP为基础改进, 采用了无锚框、解耦头、领先的标签分配策略、无非极大值抑制[23 ] 等技术, 相比YOLOv3, 提高了3%的检测精度, 并且提供了多种可选配的网络结构.众多文献基于YOLO系列算法实现了遥感图像中的实时目标检测, 但也在不同程度上面临小目标检测不敏感问题, 存在误检率或漏检率较高的情况. ...
Object detection in very high-resolution aerial images using one-stage densely connected feature pyramid network
1
2018
... 相比于传统舰船检测与识别方法[2 -5 ] , 基于深度学习的舰船目标检测识别方法的非线性拟合能力更强, 更适应于真实复杂场景下的舰船目标检测和识别.以卷积神经网络(convolutional neural network,CNN)为框架的检测模型主要分为两阶段检测和一阶段检测[6 ] .两阶段检测模型主要有R(region)-CNN[7 ] 、Fast R-CNN[8 ] 、Faster R-CNN[9 ] 、Mask R-CNN[10 ] 、空间金字塔池化网络(spatial pyramid pooling net,SPP-Net)[11 ] 等,其首先产生候选区域,然后再对该区域分类识别,具有较高的检测精度,但速度较慢,难以满足舰船目标检测应用中对实时性的要求.而以YOLO(you only look once)[12 -16 ] 、SSD(single shot multibox detector)[17 ] 、DSSD(deconvolutional SSD)[18 ] 等模型为代表的一阶段检测算法不需要区域候选阶段, 直接对目标的位置和类别进行回归, 虽检测精度相对较低, 但可达到更快的计算速度, 适合实时性较高的检测需求.为了提升YOLO的检测性能, 文献[19 ]基于tiny-YOLOv3增加了更多的卷积层以提高模型的特征提取能力, 并采用1×1的卷积核来降低特征的维度, 有效减少了训练和推理过程中的计算量.文献[20 ]将通道和空间注意力机制引入YOLO网络, 提高了舰船检测精度.文献[21 ]将骨干网络中的卷积层替换为空洞卷积来获取较大感受野, 并优化非极大值抑制算法, 提升模型检测准确率.2021年旷视科技发布了最新一代YOLO系列目标检测器YOLOX[22 ] , 以YOLOv3-SPP为基础改进, 采用了无锚框、解耦头、领先的标签分配策略、无非极大值抑制[23 ] 等技术, 相比YOLOv3, 提高了3%的检测精度, 并且提供了多种可选配的网络结构.众多文献基于YOLO系列算法实现了遥感图像中的实时目标检测, 但也在不同程度上面临小目标检测不敏感问题, 存在误检率或漏检率较高的情况. ...
1
... 相比于传统舰船检测与识别方法[2 -5 ] , 基于深度学习的舰船目标检测识别方法的非线性拟合能力更强, 更适应于真实复杂场景下的舰船目标检测和识别.以卷积神经网络(convolutional neural network,CNN)为框架的检测模型主要分为两阶段检测和一阶段检测[6 ] .两阶段检测模型主要有R(region)-CNN[7 ] 、Fast R-CNN[8 ] 、Faster R-CNN[9 ] 、Mask R-CNN[10 ] 、空间金字塔池化网络(spatial pyramid pooling net,SPP-Net)[11 ] 等,其首先产生候选区域,然后再对该区域分类识别,具有较高的检测精度,但速度较慢,难以满足舰船目标检测应用中对实时性的要求.而以YOLO(you only look once)[12 -16 ] 、SSD(single shot multibox detector)[17 ] 、DSSD(deconvolutional SSD)[18 ] 等模型为代表的一阶段检测算法不需要区域候选阶段, 直接对目标的位置和类别进行回归, 虽检测精度相对较低, 但可达到更快的计算速度, 适合实时性较高的检测需求.为了提升YOLO的检测性能, 文献[19 ]基于tiny-YOLOv3增加了更多的卷积层以提高模型的特征提取能力, 并采用1×1的卷积核来降低特征的维度, 有效减少了训练和推理过程中的计算量.文献[20 ]将通道和空间注意力机制引入YOLO网络, 提高了舰船检测精度.文献[21 ]将骨干网络中的卷积层替换为空洞卷积来获取较大感受野, 并优化非极大值抑制算法, 提升模型检测准确率.2021年旷视科技发布了最新一代YOLO系列目标检测器YOLOX[22 ] , 以YOLOv3-SPP为基础改进, 采用了无锚框、解耦头、领先的标签分配策略、无非极大值抑制[23 ] 等技术, 相比YOLOv3, 提高了3%的检测精度, 并且提供了多种可选配的网络结构.众多文献基于YOLO系列算法实现了遥感图像中的实时目标检测, 但也在不同程度上面临小目标检测不敏感问题, 存在误检率或漏检率较高的情况. ...
1
... 相比于传统舰船检测与识别方法[2 -5 ] , 基于深度学习的舰船目标检测识别方法的非线性拟合能力更强, 更适应于真实复杂场景下的舰船目标检测和识别.以卷积神经网络(convolutional neural network,CNN)为框架的检测模型主要分为两阶段检测和一阶段检测[6 ] .两阶段检测模型主要有R(region)-CNN[7 ] 、Fast R-CNN[8 ] 、Faster R-CNN[9 ] 、Mask R-CNN[10 ] 、空间金字塔池化网络(spatial pyramid pooling net,SPP-Net)[11 ] 等,其首先产生候选区域,然后再对该区域分类识别,具有较高的检测精度,但速度较慢,难以满足舰船目标检测应用中对实时性的要求.而以YOLO(you only look once)[12 -16 ] 、SSD(single shot multibox detector)[17 ] 、DSSD(deconvolutional SSD)[18 ] 等模型为代表的一阶段检测算法不需要区域候选阶段, 直接对目标的位置和类别进行回归, 虽检测精度相对较低, 但可达到更快的计算速度, 适合实时性较高的检测需求.为了提升YOLO的检测性能, 文献[19 ]基于tiny-YOLOv3增加了更多的卷积层以提高模型的特征提取能力, 并采用1×1的卷积核来降低特征的维度, 有效减少了训练和推理过程中的计算量.文献[20 ]将通道和空间注意力机制引入YOLO网络, 提高了舰船检测精度.文献[21 ]将骨干网络中的卷积层替换为空洞卷积来获取较大感受野, 并优化非极大值抑制算法, 提升模型检测准确率.2021年旷视科技发布了最新一代YOLO系列目标检测器YOLOX[22 ] , 以YOLOv3-SPP为基础改进, 采用了无锚框、解耦头、领先的标签分配策略、无非极大值抑制[23 ] 等技术, 相比YOLOv3, 提高了3%的检测精度, 并且提供了多种可选配的网络结构.众多文献基于YOLO系列算法实现了遥感图像中的实时目标检测, 但也在不同程度上面临小目标检测不敏感问题, 存在误检率或漏检率较高的情况. ...
Faster R-CNN: towards real-time object detection with region proposal networks
1
2017
... 相比于传统舰船检测与识别方法[2 -5 ] , 基于深度学习的舰船目标检测识别方法的非线性拟合能力更强, 更适应于真实复杂场景下的舰船目标检测和识别.以卷积神经网络(convolutional neural network,CNN)为框架的检测模型主要分为两阶段检测和一阶段检测[6 ] .两阶段检测模型主要有R(region)-CNN[7 ] 、Fast R-CNN[8 ] 、Faster R-CNN[9 ] 、Mask R-CNN[10 ] 、空间金字塔池化网络(spatial pyramid pooling net,SPP-Net)[11 ] 等,其首先产生候选区域,然后再对该区域分类识别,具有较高的检测精度,但速度较慢,难以满足舰船目标检测应用中对实时性的要求.而以YOLO(you only look once)[12 -16 ] 、SSD(single shot multibox detector)[17 ] 、DSSD(deconvolutional SSD)[18 ] 等模型为代表的一阶段检测算法不需要区域候选阶段, 直接对目标的位置和类别进行回归, 虽检测精度相对较低, 但可达到更快的计算速度, 适合实时性较高的检测需求.为了提升YOLO的检测性能, 文献[19 ]基于tiny-YOLOv3增加了更多的卷积层以提高模型的特征提取能力, 并采用1×1的卷积核来降低特征的维度, 有效减少了训练和推理过程中的计算量.文献[20 ]将通道和空间注意力机制引入YOLO网络, 提高了舰船检测精度.文献[21 ]将骨干网络中的卷积层替换为空洞卷积来获取较大感受野, 并优化非极大值抑制算法, 提升模型检测准确率.2021年旷视科技发布了最新一代YOLO系列目标检测器YOLOX[22 ] , 以YOLOv3-SPP为基础改进, 采用了无锚框、解耦头、领先的标签分配策略、无非极大值抑制[23 ] 等技术, 相比YOLOv3, 提高了3%的检测精度, 并且提供了多种可选配的网络结构.众多文献基于YOLO系列算法实现了遥感图像中的实时目标检测, 但也在不同程度上面临小目标检测不敏感问题, 存在误检率或漏检率较高的情况. ...
Mask R-CNN
1
2020
... 相比于传统舰船检测与识别方法[2 -5 ] , 基于深度学习的舰船目标检测识别方法的非线性拟合能力更强, 更适应于真实复杂场景下的舰船目标检测和识别.以卷积神经网络(convolutional neural network,CNN)为框架的检测模型主要分为两阶段检测和一阶段检测[6 ] .两阶段检测模型主要有R(region)-CNN[7 ] 、Fast R-CNN[8 ] 、Faster R-CNN[9 ] 、Mask R-CNN[10 ] 、空间金字塔池化网络(spatial pyramid pooling net,SPP-Net)[11 ] 等,其首先产生候选区域,然后再对该区域分类识别,具有较高的检测精度,但速度较慢,难以满足舰船目标检测应用中对实时性的要求.而以YOLO(you only look once)[12 -16 ] 、SSD(single shot multibox detector)[17 ] 、DSSD(deconvolutional SSD)[18 ] 等模型为代表的一阶段检测算法不需要区域候选阶段, 直接对目标的位置和类别进行回归, 虽检测精度相对较低, 但可达到更快的计算速度, 适合实时性较高的检测需求.为了提升YOLO的检测性能, 文献[19 ]基于tiny-YOLOv3增加了更多的卷积层以提高模型的特征提取能力, 并采用1×1的卷积核来降低特征的维度, 有效减少了训练和推理过程中的计算量.文献[20 ]将通道和空间注意力机制引入YOLO网络, 提高了舰船检测精度.文献[21 ]将骨干网络中的卷积层替换为空洞卷积来获取较大感受野, 并优化非极大值抑制算法, 提升模型检测准确率.2021年旷视科技发布了最新一代YOLO系列目标检测器YOLOX[22 ] , 以YOLOv3-SPP为基础改进, 采用了无锚框、解耦头、领先的标签分配策略、无非极大值抑制[23 ] 等技术, 相比YOLOv3, 提高了3%的检测精度, 并且提供了多种可选配的网络结构.众多文献基于YOLO系列算法实现了遥感图像中的实时目标检测, 但也在不同程度上面临小目标检测不敏感问题, 存在误检率或漏检率较高的情况. ...
Spatial pyramid pooling in deep convolutional networks for visual recognition
1
2015
... 相比于传统舰船检测与识别方法[2 -5 ] , 基于深度学习的舰船目标检测识别方法的非线性拟合能力更强, 更适应于真实复杂场景下的舰船目标检测和识别.以卷积神经网络(convolutional neural network,CNN)为框架的检测模型主要分为两阶段检测和一阶段检测[6 ] .两阶段检测模型主要有R(region)-CNN[7 ] 、Fast R-CNN[8 ] 、Faster R-CNN[9 ] 、Mask R-CNN[10 ] 、空间金字塔池化网络(spatial pyramid pooling net,SPP-Net)[11 ] 等,其首先产生候选区域,然后再对该区域分类识别,具有较高的检测精度,但速度较慢,难以满足舰船目标检测应用中对实时性的要求.而以YOLO(you only look once)[12 -16 ] 、SSD(single shot multibox detector)[17 ] 、DSSD(deconvolutional SSD)[18 ] 等模型为代表的一阶段检测算法不需要区域候选阶段, 直接对目标的位置和类别进行回归, 虽检测精度相对较低, 但可达到更快的计算速度, 适合实时性较高的检测需求.为了提升YOLO的检测性能, 文献[19 ]基于tiny-YOLOv3增加了更多的卷积层以提高模型的特征提取能力, 并采用1×1的卷积核来降低特征的维度, 有效减少了训练和推理过程中的计算量.文献[20 ]将通道和空间注意力机制引入YOLO网络, 提高了舰船检测精度.文献[21 ]将骨干网络中的卷积层替换为空洞卷积来获取较大感受野, 并优化非极大值抑制算法, 提升模型检测准确率.2021年旷视科技发布了最新一代YOLO系列目标检测器YOLOX[22 ] , 以YOLOv3-SPP为基础改进, 采用了无锚框、解耦头、领先的标签分配策略、无非极大值抑制[23 ] 等技术, 相比YOLOv3, 提高了3%的检测精度, 并且提供了多种可选配的网络结构.众多文献基于YOLO系列算法实现了遥感图像中的实时目标检测, 但也在不同程度上面临小目标检测不敏感问题, 存在误检率或漏检率较高的情况. ...
2
... 相比于传统舰船检测与识别方法[2 -5 ] , 基于深度学习的舰船目标检测识别方法的非线性拟合能力更强, 更适应于真实复杂场景下的舰船目标检测和识别.以卷积神经网络(convolutional neural network,CNN)为框架的检测模型主要分为两阶段检测和一阶段检测[6 ] .两阶段检测模型主要有R(region)-CNN[7 ] 、Fast R-CNN[8 ] 、Faster R-CNN[9 ] 、Mask R-CNN[10 ] 、空间金字塔池化网络(spatial pyramid pooling net,SPP-Net)[11 ] 等,其首先产生候选区域,然后再对该区域分类识别,具有较高的检测精度,但速度较慢,难以满足舰船目标检测应用中对实时性的要求.而以YOLO(you only look once)[12 -16 ] 、SSD(single shot multibox detector)[17 ] 、DSSD(deconvolutional SSD)[18 ] 等模型为代表的一阶段检测算法不需要区域候选阶段, 直接对目标的位置和类别进行回归, 虽检测精度相对较低, 但可达到更快的计算速度, 适合实时性较高的检测需求.为了提升YOLO的检测性能, 文献[19 ]基于tiny-YOLOv3增加了更多的卷积层以提高模型的特征提取能力, 并采用1×1的卷积核来降低特征的维度, 有效减少了训练和推理过程中的计算量.文献[20 ]将通道和空间注意力机制引入YOLO网络, 提高了舰船检测精度.文献[21 ]将骨干网络中的卷积层替换为空洞卷积来获取较大感受野, 并优化非极大值抑制算法, 提升模型检测准确率.2021年旷视科技发布了最新一代YOLO系列目标检测器YOLOX[22 ] , 以YOLOv3-SPP为基础改进, 采用了无锚框、解耦头、领先的标签分配策略、无非极大值抑制[23 ] 等技术, 相比YOLOv3, 提高了3%的检测精度, 并且提供了多种可选配的网络结构.众多文献基于YOLO系列算法实现了遥感图像中的实时目标检测, 但也在不同程度上面临小目标检测不敏感问题, 存在误检率或漏检率较高的情况. ...
... YOLO系列算法作为最典型的一阶段目标检测算法, 发展至今已历经5个版本[12 -16 ] .其中, YOLOv5提供了多个不同参数规模的模型, YOLOv5s作为其中最轻量的模型, 检测速度最快.YOLOv5s目标检测算法由4个部分组成, 分别为输入端、骨干网络、路径聚合网络和检测端, 算法流程如图 1 所示. ...
3
... 相比于传统舰船检测与识别方法[2 -5 ] , 基于深度学习的舰船目标检测识别方法的非线性拟合能力更强, 更适应于真实复杂场景下的舰船目标检测和识别.以卷积神经网络(convolutional neural network,CNN)为框架的检测模型主要分为两阶段检测和一阶段检测[6 ] .两阶段检测模型主要有R(region)-CNN[7 ] 、Fast R-CNN[8 ] 、Faster R-CNN[9 ] 、Mask R-CNN[10 ] 、空间金字塔池化网络(spatial pyramid pooling net,SPP-Net)[11 ] 等,其首先产生候选区域,然后再对该区域分类识别,具有较高的检测精度,但速度较慢,难以满足舰船目标检测应用中对实时性的要求.而以YOLO(you only look once)[12 -16 ] 、SSD(single shot multibox detector)[17 ] 、DSSD(deconvolutional SSD)[18 ] 等模型为代表的一阶段检测算法不需要区域候选阶段, 直接对目标的位置和类别进行回归, 虽检测精度相对较低, 但可达到更快的计算速度, 适合实时性较高的检测需求.为了提升YOLO的检测性能, 文献[19 ]基于tiny-YOLOv3增加了更多的卷积层以提高模型的特征提取能力, 并采用1×1的卷积核来降低特征的维度, 有效减少了训练和推理过程中的计算量.文献[20 ]将通道和空间注意力机制引入YOLO网络, 提高了舰船检测精度.文献[21 ]将骨干网络中的卷积层替换为空洞卷积来获取较大感受野, 并优化非极大值抑制算法, 提升模型检测准确率.2021年旷视科技发布了最新一代YOLO系列目标检测器YOLOX[22 ] , 以YOLOv3-SPP为基础改进, 采用了无锚框、解耦头、领先的标签分配策略、无非极大值抑制[23 ] 等技术, 相比YOLOv3, 提高了3%的检测精度, 并且提供了多种可选配的网络结构.众多文献基于YOLO系列算法实现了遥感图像中的实时目标检测, 但也在不同程度上面临小目标检测不敏感问题, 存在误检率或漏检率较高的情况. ...
... YOLO系列算法作为最典型的一阶段目标检测算法, 发展至今已历经5个版本[12 -16 ] .其中, YOLOv5提供了多个不同参数规模的模型, YOLOv5s作为其中最轻量的模型, 检测速度最快.YOLOv5s目标检测算法由4个部分组成, 分别为输入端、骨干网络、路径聚合网络和检测端, 算法流程如图 1 所示. ...
... 本文实验配置如下: 计算机操作系统为Ubuntu18.04、GPU采用NVIDIA RTX2070 SUPER, 深度学习框架采用由Ultralytics维护的YOLOv5s[16 ] .训练中, 输入图像的大小为768×768, epoch为50, batch_size为20, 初始学习率为0.01, 动量因子为0.937, 权重衰减系数为0.000 5, 且在数据预处理阶段采用Mosaic数据增强、自适应锚框计算等操作. ...
1
... 相比于传统舰船检测与识别方法[2 -5 ] , 基于深度学习的舰船目标检测识别方法的非线性拟合能力更强, 更适应于真实复杂场景下的舰船目标检测和识别.以卷积神经网络(convolutional neural network,CNN)为框架的检测模型主要分为两阶段检测和一阶段检测[6 ] .两阶段检测模型主要有R(region)-CNN[7 ] 、Fast R-CNN[8 ] 、Faster R-CNN[9 ] 、Mask R-CNN[10 ] 、空间金字塔池化网络(spatial pyramid pooling net,SPP-Net)[11 ] 等,其首先产生候选区域,然后再对该区域分类识别,具有较高的检测精度,但速度较慢,难以满足舰船目标检测应用中对实时性的要求.而以YOLO(you only look once)[12 -16 ] 、SSD(single shot multibox detector)[17 ] 、DSSD(deconvolutional SSD)[18 ] 等模型为代表的一阶段检测算法不需要区域候选阶段, 直接对目标的位置和类别进行回归, 虽检测精度相对较低, 但可达到更快的计算速度, 适合实时性较高的检测需求.为了提升YOLO的检测性能, 文献[19 ]基于tiny-YOLOv3增加了更多的卷积层以提高模型的特征提取能力, 并采用1×1的卷积核来降低特征的维度, 有效减少了训练和推理过程中的计算量.文献[20 ]将通道和空间注意力机制引入YOLO网络, 提高了舰船检测精度.文献[21 ]将骨干网络中的卷积层替换为空洞卷积来获取较大感受野, 并优化非极大值抑制算法, 提升模型检测准确率.2021年旷视科技发布了最新一代YOLO系列目标检测器YOLOX[22 ] , 以YOLOv3-SPP为基础改进, 采用了无锚框、解耦头、领先的标签分配策略、无非极大值抑制[23 ] 等技术, 相比YOLOv3, 提高了3%的检测精度, 并且提供了多种可选配的网络结构.众多文献基于YOLO系列算法实现了遥感图像中的实时目标检测, 但也在不同程度上面临小目标检测不敏感问题, 存在误检率或漏检率较高的情况. ...
1
... 相比于传统舰船检测与识别方法[2 -5 ] , 基于深度学习的舰船目标检测识别方法的非线性拟合能力更强, 更适应于真实复杂场景下的舰船目标检测和识别.以卷积神经网络(convolutional neural network,CNN)为框架的检测模型主要分为两阶段检测和一阶段检测[6 ] .两阶段检测模型主要有R(region)-CNN[7 ] 、Fast R-CNN[8 ] 、Faster R-CNN[9 ] 、Mask R-CNN[10 ] 、空间金字塔池化网络(spatial pyramid pooling net,SPP-Net)[11 ] 等,其首先产生候选区域,然后再对该区域分类识别,具有较高的检测精度,但速度较慢,难以满足舰船目标检测应用中对实时性的要求.而以YOLO(you only look once)[12 -16 ] 、SSD(single shot multibox detector)[17 ] 、DSSD(deconvolutional SSD)[18 ] 等模型为代表的一阶段检测算法不需要区域候选阶段, 直接对目标的位置和类别进行回归, 虽检测精度相对较低, 但可达到更快的计算速度, 适合实时性较高的检测需求.为了提升YOLO的检测性能, 文献[19 ]基于tiny-YOLOv3增加了更多的卷积层以提高模型的特征提取能力, 并采用1×1的卷积核来降低特征的维度, 有效减少了训练和推理过程中的计算量.文献[20 ]将通道和空间注意力机制引入YOLO网络, 提高了舰船检测精度.文献[21 ]将骨干网络中的卷积层替换为空洞卷积来获取较大感受野, 并优化非极大值抑制算法, 提升模型检测准确率.2021年旷视科技发布了最新一代YOLO系列目标检测器YOLOX[22 ] , 以YOLOv3-SPP为基础改进, 采用了无锚框、解耦头、领先的标签分配策略、无非极大值抑制[23 ] 等技术, 相比YOLOv3, 提高了3%的检测精度, 并且提供了多种可选配的网络结构.众多文献基于YOLO系列算法实现了遥感图像中的实时目标检测, 但也在不同程度上面临小目标检测不敏感问题, 存在误检率或漏检率较高的情况. ...
A target detection model based on improved tiny-YOLOv3 under the environment of mining truck
1
2019
... 相比于传统舰船检测与识别方法[2 -5 ] , 基于深度学习的舰船目标检测识别方法的非线性拟合能力更强, 更适应于真实复杂场景下的舰船目标检测和识别.以卷积神经网络(convolutional neural network,CNN)为框架的检测模型主要分为两阶段检测和一阶段检测[6 ] .两阶段检测模型主要有R(region)-CNN[7 ] 、Fast R-CNN[8 ] 、Faster R-CNN[9 ] 、Mask R-CNN[10 ] 、空间金字塔池化网络(spatial pyramid pooling net,SPP-Net)[11 ] 等,其首先产生候选区域,然后再对该区域分类识别,具有较高的检测精度,但速度较慢,难以满足舰船目标检测应用中对实时性的要求.而以YOLO(you only look once)[12 -16 ] 、SSD(single shot multibox detector)[17 ] 、DSSD(deconvolutional SSD)[18 ] 等模型为代表的一阶段检测算法不需要区域候选阶段, 直接对目标的位置和类别进行回归, 虽检测精度相对较低, 但可达到更快的计算速度, 适合实时性较高的检测需求.为了提升YOLO的检测性能, 文献[19 ]基于tiny-YOLOv3增加了更多的卷积层以提高模型的特征提取能力, 并采用1×1的卷积核来降低特征的维度, 有效减少了训练和推理过程中的计算量.文献[20 ]将通道和空间注意力机制引入YOLO网络, 提高了舰船检测精度.文献[21 ]将骨干网络中的卷积层替换为空洞卷积来获取较大感受野, 并优化非极大值抑制算法, 提升模型检测准确率.2021年旷视科技发布了最新一代YOLO系列目标检测器YOLOX[22 ] , 以YOLOv3-SPP为基础改进, 采用了无锚框、解耦头、领先的标签分配策略、无非极大值抑制[23 ] 等技术, 相比YOLOv3, 提高了3%的检测精度, 并且提供了多种可选配的网络结构.众多文献基于YOLO系列算法实现了遥感图像中的实时目标检测, 但也在不同程度上面临小目标检测不敏感问题, 存在误检率或漏检率较高的情况. ...
Attention-YOLO: 引入注意力机制的YOLO检测算法
1
2019
... 相比于传统舰船检测与识别方法[2 -5 ] , 基于深度学习的舰船目标检测识别方法的非线性拟合能力更强, 更适应于真实复杂场景下的舰船目标检测和识别.以卷积神经网络(convolutional neural network,CNN)为框架的检测模型主要分为两阶段检测和一阶段检测[6 ] .两阶段检测模型主要有R(region)-CNN[7 ] 、Fast R-CNN[8 ] 、Faster R-CNN[9 ] 、Mask R-CNN[10 ] 、空间金字塔池化网络(spatial pyramid pooling net,SPP-Net)[11 ] 等,其首先产生候选区域,然后再对该区域分类识别,具有较高的检测精度,但速度较慢,难以满足舰船目标检测应用中对实时性的要求.而以YOLO(you only look once)[12 -16 ] 、SSD(single shot multibox detector)[17 ] 、DSSD(deconvolutional SSD)[18 ] 等模型为代表的一阶段检测算法不需要区域候选阶段, 直接对目标的位置和类别进行回归, 虽检测精度相对较低, 但可达到更快的计算速度, 适合实时性较高的检测需求.为了提升YOLO的检测性能, 文献[19 ]基于tiny-YOLOv3增加了更多的卷积层以提高模型的特征提取能力, 并采用1×1的卷积核来降低特征的维度, 有效减少了训练和推理过程中的计算量.文献[20 ]将通道和空间注意力机制引入YOLO网络, 提高了舰船检测精度.文献[21 ]将骨干网络中的卷积层替换为空洞卷积来获取较大感受野, 并优化非极大值抑制算法, 提升模型检测准确率.2021年旷视科技发布了最新一代YOLO系列目标检测器YOLOX[22 ] , 以YOLOv3-SPP为基础改进, 采用了无锚框、解耦头、领先的标签分配策略、无非极大值抑制[23 ] 等技术, 相比YOLOv3, 提高了3%的检测精度, 并且提供了多种可选配的网络结构.众多文献基于YOLO系列算法实现了遥感图像中的实时目标检测, 但也在不同程度上面临小目标检测不敏感问题, 存在误检率或漏检率较高的情况. ...
Attention-YOLO: YOLO detection algorithm that introduces attention mechanism
1
2019
... 相比于传统舰船检测与识别方法[2 -5 ] , 基于深度学习的舰船目标检测识别方法的非线性拟合能力更强, 更适应于真实复杂场景下的舰船目标检测和识别.以卷积神经网络(convolutional neural network,CNN)为框架的检测模型主要分为两阶段检测和一阶段检测[6 ] .两阶段检测模型主要有R(region)-CNN[7 ] 、Fast R-CNN[8 ] 、Faster R-CNN[9 ] 、Mask R-CNN[10 ] 、空间金字塔池化网络(spatial pyramid pooling net,SPP-Net)[11 ] 等,其首先产生候选区域,然后再对该区域分类识别,具有较高的检测精度,但速度较慢,难以满足舰船目标检测应用中对实时性的要求.而以YOLO(you only look once)[12 -16 ] 、SSD(single shot multibox detector)[17 ] 、DSSD(deconvolutional SSD)[18 ] 等模型为代表的一阶段检测算法不需要区域候选阶段, 直接对目标的位置和类别进行回归, 虽检测精度相对较低, 但可达到更快的计算速度, 适合实时性较高的检测需求.为了提升YOLO的检测性能, 文献[19 ]基于tiny-YOLOv3增加了更多的卷积层以提高模型的特征提取能力, 并采用1×1的卷积核来降低特征的维度, 有效减少了训练和推理过程中的计算量.文献[20 ]将通道和空间注意力机制引入YOLO网络, 提高了舰船检测精度.文献[21 ]将骨干网络中的卷积层替换为空洞卷积来获取较大感受野, 并优化非极大值抑制算法, 提升模型检测准确率.2021年旷视科技发布了最新一代YOLO系列目标检测器YOLOX[22 ] , 以YOLOv3-SPP为基础改进, 采用了无锚框、解耦头、领先的标签分配策略、无非极大值抑制[23 ] 等技术, 相比YOLOv3, 提高了3%的检测精度, 并且提供了多种可选配的网络结构.众多文献基于YOLO系列算法实现了遥感图像中的实时目标检测, 但也在不同程度上面临小目标检测不敏感问题, 存在误检率或漏检率较高的情况. ...
基于YOLOv3的机场场面飞机检测方法
1
2019
... 相比于传统舰船检测与识别方法[2 -5 ] , 基于深度学习的舰船目标检测识别方法的非线性拟合能力更强, 更适应于真实复杂场景下的舰船目标检测和识别.以卷积神经网络(convolutional neural network,CNN)为框架的检测模型主要分为两阶段检测和一阶段检测[6 ] .两阶段检测模型主要有R(region)-CNN[7 ] 、Fast R-CNN[8 ] 、Faster R-CNN[9 ] 、Mask R-CNN[10 ] 、空间金字塔池化网络(spatial pyramid pooling net,SPP-Net)[11 ] 等,其首先产生候选区域,然后再对该区域分类识别,具有较高的检测精度,但速度较慢,难以满足舰船目标检测应用中对实时性的要求.而以YOLO(you only look once)[12 -16 ] 、SSD(single shot multibox detector)[17 ] 、DSSD(deconvolutional SSD)[18 ] 等模型为代表的一阶段检测算法不需要区域候选阶段, 直接对目标的位置和类别进行回归, 虽检测精度相对较低, 但可达到更快的计算速度, 适合实时性较高的检测需求.为了提升YOLO的检测性能, 文献[19 ]基于tiny-YOLOv3增加了更多的卷积层以提高模型的特征提取能力, 并采用1×1的卷积核来降低特征的维度, 有效减少了训练和推理过程中的计算量.文献[20 ]将通道和空间注意力机制引入YOLO网络, 提高了舰船检测精度.文献[21 ]将骨干网络中的卷积层替换为空洞卷积来获取较大感受野, 并优化非极大值抑制算法, 提升模型检测准确率.2021年旷视科技发布了最新一代YOLO系列目标检测器YOLOX[22 ] , 以YOLOv3-SPP为基础改进, 采用了无锚框、解耦头、领先的标签分配策略、无非极大值抑制[23 ] 等技术, 相比YOLOv3, 提高了3%的检测精度, 并且提供了多种可选配的网络结构.众多文献基于YOLO系列算法实现了遥感图像中的实时目标检测, 但也在不同程度上面临小目标检测不敏感问题, 存在误检率或漏检率较高的情况. ...
Airport scene aircraft detection method based on YOLOv3
1
2019
... 相比于传统舰船检测与识别方法[2 -5 ] , 基于深度学习的舰船目标检测识别方法的非线性拟合能力更强, 更适应于真实复杂场景下的舰船目标检测和识别.以卷积神经网络(convolutional neural network,CNN)为框架的检测模型主要分为两阶段检测和一阶段检测[6 ] .两阶段检测模型主要有R(region)-CNN[7 ] 、Fast R-CNN[8 ] 、Faster R-CNN[9 ] 、Mask R-CNN[10 ] 、空间金字塔池化网络(spatial pyramid pooling net,SPP-Net)[11 ] 等,其首先产生候选区域,然后再对该区域分类识别,具有较高的检测精度,但速度较慢,难以满足舰船目标检测应用中对实时性的要求.而以YOLO(you only look once)[12 -16 ] 、SSD(single shot multibox detector)[17 ] 、DSSD(deconvolutional SSD)[18 ] 等模型为代表的一阶段检测算法不需要区域候选阶段, 直接对目标的位置和类别进行回归, 虽检测精度相对较低, 但可达到更快的计算速度, 适合实时性较高的检测需求.为了提升YOLO的检测性能, 文献[19 ]基于tiny-YOLOv3增加了更多的卷积层以提高模型的特征提取能力, 并采用1×1的卷积核来降低特征的维度, 有效减少了训练和推理过程中的计算量.文献[20 ]将通道和空间注意力机制引入YOLO网络, 提高了舰船检测精度.文献[21 ]将骨干网络中的卷积层替换为空洞卷积来获取较大感受野, 并优化非极大值抑制算法, 提升模型检测准确率.2021年旷视科技发布了最新一代YOLO系列目标检测器YOLOX[22 ] , 以YOLOv3-SPP为基础改进, 采用了无锚框、解耦头、领先的标签分配策略、无非极大值抑制[23 ] 等技术, 相比YOLOv3, 提高了3%的检测精度, 并且提供了多种可选配的网络结构.众多文献基于YOLO系列算法实现了遥感图像中的实时目标检测, 但也在不同程度上面临小目标检测不敏感问题, 存在误检率或漏检率较高的情况. ...
2
... 相比于传统舰船检测与识别方法[2 -5 ] , 基于深度学习的舰船目标检测识别方法的非线性拟合能力更强, 更适应于真实复杂场景下的舰船目标检测和识别.以卷积神经网络(convolutional neural network,CNN)为框架的检测模型主要分为两阶段检测和一阶段检测[6 ] .两阶段检测模型主要有R(region)-CNN[7 ] 、Fast R-CNN[8 ] 、Faster R-CNN[9 ] 、Mask R-CNN[10 ] 、空间金字塔池化网络(spatial pyramid pooling net,SPP-Net)[11 ] 等,其首先产生候选区域,然后再对该区域分类识别,具有较高的检测精度,但速度较慢,难以满足舰船目标检测应用中对实时性的要求.而以YOLO(you only look once)[12 -16 ] 、SSD(single shot multibox detector)[17 ] 、DSSD(deconvolutional SSD)[18 ] 等模型为代表的一阶段检测算法不需要区域候选阶段, 直接对目标的位置和类别进行回归, 虽检测精度相对较低, 但可达到更快的计算速度, 适合实时性较高的检测需求.为了提升YOLO的检测性能, 文献[19 ]基于tiny-YOLOv3增加了更多的卷积层以提高模型的特征提取能力, 并采用1×1的卷积核来降低特征的维度, 有效减少了训练和推理过程中的计算量.文献[20 ]将通道和空间注意力机制引入YOLO网络, 提高了舰船检测精度.文献[21 ]将骨干网络中的卷积层替换为空洞卷积来获取较大感受野, 并优化非极大值抑制算法, 提升模型检测准确率.2021年旷视科技发布了最新一代YOLO系列目标检测器YOLOX[22 ] , 以YOLOv3-SPP为基础改进, 采用了无锚框、解耦头、领先的标签分配策略、无非极大值抑制[23 ] 等技术, 相比YOLOv3, 提高了3%的检测精度, 并且提供了多种可选配的网络结构.众多文献基于YOLO系列算法实现了遥感图像中的实时目标检测, 但也在不同程度上面临小目标检测不敏感问题, 存在误检率或漏检率较高的情况. ...
... YOLOv5s模型的特征融合模块采用PANet[22 ] 的结构, 由特征金字塔网络(feature pyramid network, FPN)[27 ] 和路径聚合网络(path aggregation network, PAN)两个核心结构组成.其使用一个自顶向下(FPN)和自底向上(PAN)的双向融合网络对骨干网络提取的特征图进行融合, 使每个特征层都能够同时具有深层特征的语义信息和浅层特征的细节信息, 在令融合特征拥有上下文信息的同时增强了骨干网络的表征能力.但是, 主要用于检测小目标的特征图是由浅层特征和来自深层上采样后的特征构成的, 深层特征在提取过程中经过了多次下采样, 且在融合过程中经过多层传递后信息丢失较为严重, 使得用于检测小目标的融合特征缺少了较为丰富的语义信息. ...
1
... 相比于传统舰船检测与识别方法[2 -5 ] , 基于深度学习的舰船目标检测识别方法的非线性拟合能力更强, 更适应于真实复杂场景下的舰船目标检测和识别.以卷积神经网络(convolutional neural network,CNN)为框架的检测模型主要分为两阶段检测和一阶段检测[6 ] .两阶段检测模型主要有R(region)-CNN[7 ] 、Fast R-CNN[8 ] 、Faster R-CNN[9 ] 、Mask R-CNN[10 ] 、空间金字塔池化网络(spatial pyramid pooling net,SPP-Net)[11 ] 等,其首先产生候选区域,然后再对该区域分类识别,具有较高的检测精度,但速度较慢,难以满足舰船目标检测应用中对实时性的要求.而以YOLO(you only look once)[12 -16 ] 、SSD(single shot multibox detector)[17 ] 、DSSD(deconvolutional SSD)[18 ] 等模型为代表的一阶段检测算法不需要区域候选阶段, 直接对目标的位置和类别进行回归, 虽检测精度相对较低, 但可达到更快的计算速度, 适合实时性较高的检测需求.为了提升YOLO的检测性能, 文献[19 ]基于tiny-YOLOv3增加了更多的卷积层以提高模型的特征提取能力, 并采用1×1的卷积核来降低特征的维度, 有效减少了训练和推理过程中的计算量.文献[20 ]将通道和空间注意力机制引入YOLO网络, 提高了舰船检测精度.文献[21 ]将骨干网络中的卷积层替换为空洞卷积来获取较大感受野, 并优化非极大值抑制算法, 提升模型检测准确率.2021年旷视科技发布了最新一代YOLO系列目标检测器YOLOX[22 ] , 以YOLOv3-SPP为基础改进, 采用了无锚框、解耦头、领先的标签分配策略、无非极大值抑制[23 ] 等技术, 相比YOLOv3, 提高了3%的检测精度, 并且提供了多种可选配的网络结构.众多文献基于YOLO系列算法实现了遥感图像中的实时目标检测, 但也在不同程度上面临小目标检测不敏感问题, 存在误检率或漏检率较高的情况. ...
1
... 输入端对光学遥感图像进行Mosaic数据增强、自适应锚框计算等数据预处理操作; 骨干网络采用跨阶段局部网络Darknet53[24 ] 网络结构, 用以提取不同尺度的特征图; 路径聚合网络(path aggregation network, PANet)[25 ] 将由主干网络提取的不同尺度特征图进行融合, 增强特征表达能力, 最后输出3个尺度的特征图用于后续检测.其中, 较深层的特征图主要负责大目标的检测, 较浅层的特征图主要负责小目标的检测.检测端分别针对各尺度融合特征图的每个网格输出多个预测框及置信度, 最终通过非极大值抑制(non-maximum suppression, NMS)算法[26 ] 筛选出最终的检测框. ...
1
... 输入端对光学遥感图像进行Mosaic数据增强、自适应锚框计算等数据预处理操作; 骨干网络采用跨阶段局部网络Darknet53[24 ] 网络结构, 用以提取不同尺度的特征图; 路径聚合网络(path aggregation network, PANet)[25 ] 将由主干网络提取的不同尺度特征图进行融合, 增强特征表达能力, 最后输出3个尺度的特征图用于后续检测.其中, 较深层的特征图主要负责大目标的检测, 较浅层的特征图主要负责小目标的检测.检测端分别针对各尺度融合特征图的每个网格输出多个预测框及置信度, 最终通过非极大值抑制(non-maximum suppression, NMS)算法[26 ] 筛选出最终的检测框. ...
1
... 输入端对光学遥感图像进行Mosaic数据增强、自适应锚框计算等数据预处理操作; 骨干网络采用跨阶段局部网络Darknet53[24 ] 网络结构, 用以提取不同尺度的特征图; 路径聚合网络(path aggregation network, PANet)[25 ] 将由主干网络提取的不同尺度特征图进行融合, 增强特征表达能力, 最后输出3个尺度的特征图用于后续检测.其中, 较深层的特征图主要负责大目标的检测, 较浅层的特征图主要负责小目标的检测.检测端分别针对各尺度融合特征图的每个网格输出多个预测框及置信度, 最终通过非极大值抑制(non-maximum suppression, NMS)算法[26 ] 筛选出最终的检测框. ...
1
... YOLOv5s模型的特征融合模块采用PANet[22 ] 的结构, 由特征金字塔网络(feature pyramid network, FPN)[27 ] 和路径聚合网络(path aggregation network, PAN)两个核心结构组成.其使用一个自顶向下(FPN)和自底向上(PAN)的双向融合网络对骨干网络提取的特征图进行融合, 使每个特征层都能够同时具有深层特征的语义信息和浅层特征的细节信息, 在令融合特征拥有上下文信息的同时增强了骨干网络的表征能力.但是, 主要用于检测小目标的特征图是由浅层特征和来自深层上采样后的特征构成的, 深层特征在提取过程中经过了多次下采样, 且在融合过程中经过多层传递后信息丢失较为严重, 使得用于检测小目标的融合特征缺少了较为丰富的语义信息. ...
1
... YOLOv5s模型使用参数为0.1的Leaky ReLU函数作为激活函数, 该函数在大于0的定义域上梯度为1, 有利于网络的学习; 在小于0的定义域上梯度是一个很小的非零值, 能够避免神经元未被激活时出现的死亡现象.然而Leaky ReLU函数也存在弊端, 一方面, 其分别在正负两个区间内都是线性函数, 限制了模型的表达能力; 另一方面, 其在正负两个方向上都是无界的, 这将影响网络的收敛速度.为改善这种情况, 本文选择Swish函数[28 ] 作为网络的激活函数, 其表达式如下所示: ...
1
... 本文实验数据采用Kaggle平台公开的用于舰船检测的遥感图像数据集[29 ] , 数据集中的舰船目标普遍较小且位置分布随机, 如图 4 所示, 同时包含有陆地、港口、海面等背景并受到云雾、雨、雪等多种气候干扰.由于该数据集中绝大多数图像仅含1个目标, 为避免样本中目标个数的不均衡, 对数据进行抽样, 减少仅含1个目标的图像数量, 选用其中8 204张图像进行实验. ...
1
... 为说明改进模型能够提取到更鲁棒的特征, 采用Grad-Cam++[30 ] 方法, 在模型的检测端对各检测头的特征图进行加权组合, 获得含有类别信息的显著图, 即类激活图.图 5 分别绘制了YOLOv5s原始模型检测端以及改进模型检测端的类激活图.通过比较可以看出, 原始模型的小目标检测头表现尚可, 能够标示出目标存在区域, 但对比度相对不够明显, 而中目标检测头和大目标检测头则对背景区域投入了较大关注, 相比之下改进模型的两个检测头上都将注意力更多集中于目标区域, 且较为突出, 有效地抑制了背景区域, 但也同时存在一些可能引起错误检测的背景信息未被完全过滤.从检测头的维度进行比较可以看出, 主要针对大目标的检测头对于较小的舰船目标的检测贡献较少, 更多将注意力投向了背景区域.图 6 展示了改进模型在误检及漏检问题上相较于原始模型的改善, 分别选取两张图像说明改进模型在舰船目标大小差异大、目标间位置关系复杂等情况下的检测效果.图 6(a) 反映了改进模型对原始模型漏检情况的改善, 对于尺寸较小但航迹明显的目标和大目标旁紧邻的小目标取得了更好的检测效果, 说明改进模型确实能够提取到更具鲁棒性的特征以进行目标判别.图 6(b) 反映了改进模型在检测准确率上的改善, 相较于原始模型将没有停靠船舶的码头和靠近图片边缘的云雾识别为船只, 改进模型采取了更为严格的判别标准, 减少了误检情况的出现, 取得了更好的检测效果. ...





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}