
系统工程与电子技术 ›› 2024, Vol. 46 ›› Issue (4): 1297-1308.doi: 10.12305/j.issn.1001-506X.2024.04.18
张梦钰, 豆亚杰, 陈子夷, 姜江, 杨克巍, 葛冰峰
收稿日期:2022-04-03
出版日期:2024-03-25
发布日期:2024-03-25
通讯作者:
豆亚杰
作者简介:张梦钰 (1999—), 女, 硕士研究生, 主要研究方向为军事系统工程智能决策技术基金资助:Mengyu ZHANG, Yajie DOU, Ziyi CHEN, Jiang JIANG, Kewei YANG, Bingfeng GE
Received:2022-04-03
Online:2024-03-25
Published:2024-03-25
Contact:
Yajie DOU
摘要:
随着大数据、云计算、物联网等一系列新兴技术的大量涌现, 人工智能技术不断取得突破性进展。深度强化学习(deep reinforcement learning, DRL)技术作为人工智能的最新成果之一, 正被逐渐引入军事领域中, 促使军事领域走向信息化和智能化。在未来战争作战模式及军队发展建设中, 网络化、信息化、智能化和无人化形成重要特征, 已经成为不可逆转的趋势。因此, 在回顾了DRL基本原理和主要算法的基础上, 对当前DRL在武器装备、网络安全、无人机(unmanned aerial vehicle, UAV)编队、智能决策与博弈等方面的应用现状进行了系统的梳理与总结。最后, 针对实际推进DRL技术在军事领域应用落地所面临的一系列问题和挑战, 提供了未来进一步研究的思路。
中图分类号:
张梦钰, 豆亚杰, 陈子夷, 姜江, 杨克巍, 葛冰峰. 深度强化学习及其在军事领域中的应用综述[J]. 系统工程与电子技术, 2024, 46(4): 1297-1308.
Mengyu ZHANG, Yajie DOU, Ziyi CHEN, Jiang JIANG, Kewei YANG, Bingfeng GE. Review of deep reinforcement learning and its applications in military field[J]. Systems Engineering and Electronics, 2024, 46(4): 1297-1308.
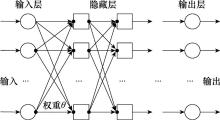
图1
ANN的结构"

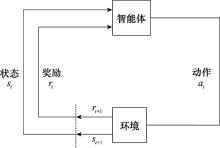
图2
RL基本过程"

表1
基于值函数的DRL主要算法"
| 名称 | 时间/年份 | 主要改进 | 优势 |
| DQN[ | 2013 | 引入深度CNN和经验回放 | - |
| Nature DQN[ | 2015 | 提出使用两个Q网络 | 相比DQN更加稳定 |
| Double DQN[ | 2016 | 使用不同值函数分别进行动作选择和评估 | 克服Q学习中过于乐观的值估计 |
| Dueling DQN[ | 2016 | 将网络划分为价值网络和优势网络 | 网络结构和RL算法更好地结合 |
| D3QN[ | 2018 | 整合Double DQN和Dueling DQN | 收敛速度更快、更稳定 |
| Rainbow DQN[ | 2018 | 整合DQN算法中的6种变体 | 训练效果有巨大进步, 能适用于各种场景 |
表2
基于策略梯度的DRL主要算法"
| 名称 | 时间/年份 | 主要改进 | 优势 |
| DDPG[ | 2015 | 引入经验回放、目标值网络和目标策略网络 | 可以用来解决连续控制RL领域问题 |
| TD3[ | 2018 | 使用两套网络表示不同Q值 | 抑制Q值过高估计 |
| TPRO[ | 2015 | 使用优势函数保证持续优化 | 提高了算法的采样效率 |
| PPO[ | 2017 | 利用新旧策略比例限制新策略更新幅度 | 进一步提升了算法采样效率 |
| DPPO[ | 2017 | 网络多线程并行 | 避免参数训练的震荡 |
| A3C[ | 2016 | 不同的智能体并行探索 | 训练时间短 |
| A2C[ | 2017 | 同步控制 | 训练效果优于A3C |
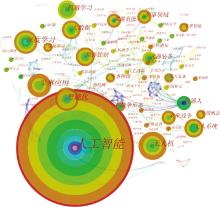
图3
人工智能技术与军事领域结合应用图谱"

表3
DRL在军事领域中的应用"
| 应用领域 | 文献 | 基本算法 | 方法改进创新 | 具体问题 |
| 武器装备 | [ | PPO | - | 武器装备组合推荐 |
| [ | DQN、Double DQN | 使用当前状态的Q值替换公式中下一状态的Q值 | 武器装备动态目标分配 | |
| 网络安全 | [ | FINDER框架(DQN) | 归纳式图表式学习、小型合成网络训练 | 复杂网络结构优化 |
| [ | FINDER框架 | 识别出关键节点后结合遗传算法改进网络结构 | 军用通信网络结构优化 | |
| [ | DRL-BWO | 利用BWO算法对深度信念网络的参数进行优化 | 网络入侵检测 | |
| 无人机编队 | [ | MAJPPO | 采用滑动窗口平均计算集中的状态价值函数 | 多无人机协同编队控制 |
| [ | DQN | 提出优先采样策略替代传统DQN中的随机采样 | 无人机避障、编队、对抗 | |
| [ | DDPG | 基于滑动平均值的软更新策略 | 无人机集群协同 | |
| 智能决策与博弈 | [ | DQN | 周期性冻结策略使智能体与对手智能体交替训练 | 智能策略对抗 |
| [ | DQN、DDPG | 战斗规则辅助训练 | 多智能体作战训练 | |
| [ | TD3 | - | 机动决策 | |
| [ | DDPG | 引入正则化器、提出最大熵逆RL算法对奖励进行规划 | 机动决策 | |
| [ | DDPG | 优先级经验重放、混合双噪声探索、多智能体单训练 | 多智能体机动决策 | |
| 情报 | [ | DQN | 结合机器学习分类器学习模式 | 威胁识别 |
| 仿真训练 | [ | MADDPG | 不频繁反馈进行学习、密集奖励系统 | 飞行员训练 |
| 调度 | [ | A2C | 状态的图像表示 | 多资源约束的多项目调度 |
| 路径规划 | [ | DQN | 先验知识和先验规则改进算法 | 机器人路径规划 |
| [ | Double DQN | 随机设置目标位置扩大样本池状态空间分布 | 机器人路径规划 | |
| [ | D3QN | ε-贪婪策略和启发式搜索规则相结合对动作选择策略进行改进 | 无人机路径规划 |
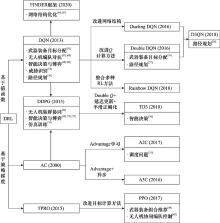
图4
DRL方法演化图"

| 1 | 郭若冰, 司光亚, 贺筱媛. 迎接智能化时代军事指挥面临的新挑战——全军"战争复杂性与信息化战争模拟"研讨会观点综述[J]. 中国军事科学, 2016, (5): 149- 156. |
| GUO R B , SI G Y , HE X Y . Meet new challenges to military command in the intelligence era-asummary of the PLA symposium on "the complexity of war and the simulation of information-izedwarfare"[J]. China Military Science, 2016, (5): 149- 156. | |
| 2 | 刘志刚. 眺望下一场变革——关于后信息时代军队建设发展的断想[EB/OL]. [2022-03-07]. http://www.81.cn/yw/2021-09/07/content_10086965.html. |
| LIU Z G. Overlooking the next revolution-thoughts on the development of military construction in the post information age[EB/OL]. [2022-03-07]. http://www.81.cn/yw/2021-09/07/content_10086965.html. | |
| 3 | 吴明曦. 智能化战争时代正在加速到来[J]. 学术前沿, 2021, (10): 35- 55. |
| WU M X . The era of intelligent war is coming rapidly[J]. Frontiers, 2021, (10): 35- 55. | |
| 4 |
LIU S F , WANG Y , YANG X , et al. Deep learning in medical ultrasound analysis: a review[J]. Engineering, 2019, 5 (2): 261- 275.
doi: 10.1016/j.eng.2018.11.020 |
| 5 | POLYDOROS A S , NALPANTIDIS L . Survey of model-based reinforcement learning: applications on robotics[J]. Journal of Intelligent & Robotic Systems, 2017, 86 (2): 153- 173. |
| 6 | LI Y X. Deep reinforcement learning: an overview[EB/OL]. [2022-03-20]. https://arXiv.org/abs/1701.07274v5. |
| 7 | FRANÇOIS-LAVET V , HENDERSON P , ISLAM R , et al. An introduction to deep reinforcement learning[J]. Foundations and Trends in Machine Learning, 2018, 11 (3/4): 219- 354. |
| 8 |
AZAR A T , KOUBAA A , MOHAMED N , et al. Drone deep reinforcement learning: a review[J]. Electronics, 2021, 10 (9): 999- 1029.
doi: 10.3390/electronics10090999 |
| 9 | LUONG N C , HOANG D T , GONG S , et al. Applications of deep reinforcement learning in communications and networking: a survey[J]. IEEE Communications Surveys & Tutorials, 2019, 21 (4): 3133- 3174. |
| 10 | 孔松涛, 刘池池, 史勇, 等. 深度强化学习在智能制造中的应用展望综述[J]. 计算机工程与应用, 2021, 57 (2): 49- 59. |
| KONG S T , LIU C C , SHI Y , et al. Review of application prospect of deep reinforcement learning in intelligent manufacturing[J]. Computer Engineering and Applications, 2021, 57 (2): 49- 59. | |
| 11 |
ABIODUN O I , JANTAN A , OMOLARA A E , et al. State-of-the-art in artificial neural network applications: a survey[J]. Heliyon, 2018, 4 (11): e00938.
doi: 10.1016/j.heliyon.2018.e00938 |
| 12 |
LECUN. Y , BENGIO Y , HINTON G . Deep learning[J]. Nature, 2015, 521 (7553): 436- 444.
doi: 10.1038/nature14539 |
| 13 | KRIZHEVSKY A, SUTSKEVER I, HINTON G E. Imagenet classification with deep convolutional neural networks[C]//Proc. of the International Conference on Neural Information Processing Systems, 2012: 1097-1105. |
| 14 | SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition[C]//Proc. of the International Conference on Learning Representations, 2015. |
| 15 | LIN M, CHEN Q, YAN S C. Network in network[C]//Proc. of the International Conference on Learning Representations, 2014. |
| 16 | HE K M, ZHANG X Y, REN S Q, et al. Deep residual learning for image recognition[C]//Proc. of the IEEE Conference on Computer Vision and Pattern Recognition, 2016: 770-778. |
| 17 |
SHERSTINSKY A . Fundamentals of recurrent neural network (RNN) and long short-term memory (LSTM) network[J]. Physica D: Nonlinear Phenomena, 2020, 404, 132306.
doi: 10.1016/j.physd.2019.132306 |
| 18 |
HOCHREITER S , SCHMIDHUBER J . Long short-term memory[J]. Neural Computation, 1997, 9 (8): 1735- 1780.
doi: 10.1162/neco.1997.9.8.1735 |
| 19 | GREFF K , SRIVASTAVA R K , KOUTNÍK J , et al. LSTM: a search space odyssey[J]. IEEE Trans.on Neural Networks and Learning Systems, 2016, 28 (10): 2222- 2232. |
| 20 | SUTTON R S , BARTO A G . Reinforcement learning: an introduction[M]. Cambridge: MIT Press, 2018. |
| 21 | HA D, SCHMIDHUBER J. World models[EB/OL]. [2022-03-09]. https://arxiv.53yu.com/abs/1803.10122. |
| 22 | RACANIERE S, WEBER T, REICHERT D, et al. Imagination-augmented agents for deep reinforcement learning[C]//Proc. of the 30th Conference on Neural Information Processing Systems, 2017: 5690-5701. |
| 23 | CHEN J X . The evolution of computing: AlphaGo[J]. Computing in Science & Engineering, 2016, 18 (4): 4- 7. |
| 24 | TIAN Y D, MA J, GONG Q C, et al. ELF OpenGo: an analysis and open reimplementation of AlphaZero[C]//Proc. of the International Conference on Machine Learning, 2019: 6244-6253. |
| 25 |
SINGH S , JAAKKOLA T , LITTMAN M L , et al. Convergence results for single-step on-policy reinforcement-learning algorithms[J]. Machine Learning, 2000, 38 (3): 287- 308.
doi: 10.1023/A:1007678930559 |
| 26 | WATKINS C J C H , DAYAN P . Q-learning[J]. Machine Learning, 1992, 8 (3): 279- 292. |
| 27 |
PANOV A I , YAKOVLEV K S , SUVOROV R . Grid path planning with deep reinforcement learning: preliminary results[J]. Procedia Computer Science, 2018, 123, 347- 353.
doi: 10.1016/j.procs.2018.01.054 |
| 28 | 熊鑫立, 杨林, 李克超. 基于马尔可夫决策过程的动态目标防御策略优化方法[J]. 武汉大学学报(理学版), 2020, 66 (2): 141- 148. |
| XIONG X L , YANG L , LI K C . A strategy optimization model of moving target defense based on Markov[J]. Journal of Wuhan University (Natural Science Edition), 2020, 66 (2): 141- 148. | |
| 29 | FORTUNATO M, AZAR M G, PIOT B, et al. Noisy networks for exploration[C]//Proc. of the 6th International Conference on Learning Representations, 2018. |
| 30 | SUTTON R S , MCALLESTER D , SINGH S , et al. Policy gradient methods for reinforcement learning with function approximation[J]. Advances in Neural Information Processing Systems, 2000, 12, 1057- 1063. |
| 31 | MNIH V, KAVUKCUOGLU K, SILVER D, et al. Playing atari with deep reinforcement learning[EB/OL]. [2022-03-20]. https://arXiv.org/abs/1312.5602v1. |
| 32 |
MNIH V , KAVUKCUOGLU K , SILVER D , et al. Human-level control through deep reinforcement learning[J]. Nature, 2015, 518 (7540): 529- 533.
doi: 10.1038/nature14236 |
| 33 | VAN H H, GUEZ A, SILVER D. Deep reinforcement learning with double Q-learning[C]//Proc. of the AAAI Conference on Artificial Intelligence, 2016. |
| 34 | WANG Z, SCHAUL T, HESSEL M, et al. Dueling network architectures for deep reinforcement learning[C]//Proc. of the International Conference on Machine Learning, 2016: 1995-2003. |
| 35 | HUANG Y, WEI G L, WANG Y X. VD D3QN: the variant of double deep Q-learning network with dueling architecture[C]//Proc. of the 37th Chinese Control Conference, 2018: 9130-9135. |
| 36 | HESSEL M, MODAYIL J, VAN H H, et al. Rainbow: combining improvements in deep reinforcement learning[C]//Proc. of the 32nd AAAI Conference on Artificial Intelligence, 2018: 3215-3222. |
| 37 | LILLICRAP T P, HUNT J J, PRITZEL A, et al. Continuous control with deep reinforcement learning[C]//Proc. of the International Conference on Learning Representations, 2016. |
| 38 | HAARNOJA T, ZHOU A, ABBEEL P, et al. Soft actor-critic: off-policy maximum entropy deep reinforcement learning with a stochastic actor[C]//Proc. of the International Conference on Machine Learning, 2018: 1861-1870. |
| 39 | SCHULMAN J, LEVINE S, ABBEEL P, et al. Trust region policy optimization[C]//Proc. of the International Conference on Machine Learning, 2015: 1889-1897. |
| 40 | SCHULMAN J, WOLSKI F, DHARIWAL P, et al. Proximal policy optimization algorithms[EB/OL]. [2023-03-20]. https://arXiv.org/abs/1707.06347. |
| 41 | HEESS N, TB D, SRIRAM S, et al. Emergence of locomotion behaviours in rich environments[EB/OL]. [2023-03-20]. https://arXiv.org/abs/1707.02286. |
| 42 | MNIH V, BADIA A P, MIRZA M, et al. Asynchronous methods for deep reinforcement learning[C]//Proc. of the International Conference on Machine Learning, 2016: 1928-1937. |
| 43 | SCHULMAN J, WOLSKI F, DHARIWAL P, et al. Proximal policy optimization algorithms[EB/OL]. [2023-03-20]. https://arXiv.org/abs/1707.06347. |
| 44 | 张骁雄, 葛冰峰, 姜江, 等. 面向能力需求的武器装备组合规划模型与算法[J]. 国防科技大学学报, 2017, 39 (1): 102- 108. |
| ZHANG X X , GE B F , JIANG J , et al. Capability requirements oriented weapons portfolio planning model and algorithm[J]. Journal of National University of Defense Technology, 2017, 39 (1): 102- 108. | |
| 45 |
LI J C , GE B F , JIANG J , et al. High-end weapon equipment portfolio selection based on a heterogeneousnetwork model[J]. Journal of Global Optimization, 2020, 78 (4): 743- 761.
doi: 10.1007/s10898-018-0687-1 |
| 46 | 豆亚杰. 武器系统组合选择问题与决策方法研究[D]. 长沙: 国防科技大学, 2016. |
| DOU Y J. Research on weapon system portfolio selection problems and decision methods[D]. Changsha: National University of Defense Technology, 2016. | |
| 47 | 孙建彬, 邢立宇. 基于遗传算法的武器系统组合优化方法[J]. 价值工程, 2011, 30 (29): 9- 10. |
| SUN J B , XING L Y . The method of weapons system combinatorial optimization based on genetic algorithm[J]. Value Engineering, 2011, 30 (29): 9- 10. | |
| 48 | 杜波. 基于代理模型的武器装备体系优化方法研究[D]. 长沙: 国防科技大学, 2010. |
| DU B. Research on optimization methods of weapon equipment system of systems based on surrogate model[D]. Changsha: National University of Defense Technology, 2010. | |
| 49 | 张骁雄, 丁松, 李明浩, 等. 强化学习在多阶段装备组合规划问题中的应用[J]. 国防科技大学学报, 2021, 43 (5): 127- 136. |
| ZHANG X X , DING S , LI M H , et al. Application of reinforcement learning in multi-period weapon portfolio planning problems[J]. Journal of National University of Defense Technology, 2021, 43 (5): 127- 136. | |
| 50 | 文东日, 陈小虎, 李文, 等. 基于深度强化学习的装备组合运用方法[J]. 指挥控制与仿真, 2021, 43 (6): 135- 140. |
| WEN D R , CHEN X H , LI W , et al. Method of equipment combination application based on deep reinforcement learning[J]. Command Control & Simulation, 2021, 43 (6): 135- 140. | |
| 51 | 黄亭飞, 程光权, 黄魁华, 等. 基于DQN的多类型拦截装备复合式反无人机任务分配方法[J]. 控制与决策, 2022, 37 (1): 142- 150. |
| HUANG T F , CHENG G Q , HUANG K H , et al. Task assignment method of compound anti-drone based on DQN for multi-type interception equipment[J]. Control and Decision, 2022, 37 (1): 142- 150. | |
| 52 | 杨艳萍, 叶锡庆, 张明安, 等. 战场网络战基本模型研究[J]. 系统仿真学报, 2011, 23 (5): 1015-1020, 1038. |
| YANG Y P , YE X Q , ZHANG M A , et al. Research on basic models for battlefield network war[J]. Journal of System Simulation, 2011, 23 (5): 1015-1020, 1038. | |
| 53 | 杨芷柔, 张虎, 刘静, 等. 节点攻击策略下的军事通信网络结构优化算法[J]. 系统工程与电子技术, 2021, 43 (7): 1848- 1855. |
| YANG Z R , ZHANG H , LIU J , et al. Optimization algorithm of military communication network structure under node attack strategy[J]. Systems Engineering and Electronics, 2021, 43 (7): 1848- 1855. | |
| 54 | 刘同林, 杨芷柔, 张虎, 等. 基于复杂网络的军事通信网络建模与性能分析[J]. 系统工程与电子技术, 2020, 42 (12): 2892- 2898. |
| LIU T L , YANG Z R , ZHANG H , et al. Modeling and performance analysis of military communication network based on complex network[J]. Systems Engineering and Electronics, 2020, 42 (12): 2892- 2898. | |
| 55 | 王梓行, 姜大立, 漆磊, 等. 基于冗余度的复杂网络抗毁性及节点重要度评估模型[J]. 复杂系统与复杂性科学, 2020, 17 (3): 78- 85. |
| WANG Z X , JIANG D L , QI L , et al. Complex network invulnerability and node importance evaluation model based on redundancy[J]. Complex Systems and Complexity Science, 2020, 17 (3): 78- 85. | |
| 56 |
ZENG L , SUN Y Z , LIU Y Y , et al. Finding key players in complex networks through deep reinforcement learning[J]. Nature Machine Intelligence, 2020, 2 (6): 317- 324.
doi: 10.1038/s42256-020-0177-2 |
| 57 | XU Z A, FAN Z Q. Topological structure optimization algorithm of military communication network based on genetic algorithm[C]//Proc. of the IEEE International Conference on Computer Engineering and Application, 2021: 11-18. |
| 58 | PRAVEENA V , VIJAYARAJ A , CHINNASAMY P , et al. Optimal deep reinforcement learning for intrusion detection in UAVs[J]. CMC-Computers Materials& Continua, 2022, 70 (2): 2639- 2653. |
| 59 | 郑莹, 段庆洋, 林利祥, 等. 深度强化学习在典型网络系统中的应用综述[J]. 无线电通信技术, 2020, 46 (6): 603- 623. |
| ZHENG Y , DUAN Q Y , LIN L X , et al. A survey on the applications of deep reinforcement learning in classical networking systems[J]. Radio Communications Technology, 2020, 46 (6): 603- 623. | |
| 60 | 洪志鹰. 基于深度强化学习的多智能体编队问题研究[D]. 南京: 东南大学, 2020. |
| HONG Z Y. Deep reinforcement learning based multi-agent formation methods[D]. Nanjing: Southeast University, 2020. | |
| 61 | 奚之飞, 徐安, 寇英信, 等. 多机协同空战机动决策流程[J]. 系统工程与电子技术, 2020, 42 (2): 381- 389. |
| XI Z F , XU A , KOU Y X , et al. Decision process of multi-aircraft cooperative air combat maneuver[J]. Systems Engineering and Electronics, 2020, 42 (2): 381- 389. | |
| 62 |
ZHAO W W , CHU H R , MIAO X K , et al. Research on the multiagent joint proximal policy optimization algorithm controlling cooperative fixed-wing UAV obstacle avoidance[J]. Sensors, 2020, 20 (16): 4546- 4562.
doi: 10.3390/s20164546 |
| 63 |
HU J W , WANG L H , HU T M , et al. Autonomous maneuver decision making of dual-UAV cooperative air combat based on deep reinforcement learning[J]. Electronics, 2022, 11 (3): 467- 489.
doi: 10.3390/electronics11030467 |
| 64 | 张耀中, 许佳林, 姚康佳, 等. 基于DDPG算法的无人机集群追击任务[J]. 航空学报, 2020, 41 (10): 314- 326. |
| ZHANG Y Z , XU J L , YAO K J , et al. Pursuit missions for UAV swarms based on DDPG algorithm[J]. Acta Aeronautica et Astronautica Sinica, 2020, 41 (10): 314- 326. | |
| 65 |
SILVER D , HUANG A , MADDISON C J , et al. Mastering the game of go with deep neural networks and tree search[J]. Nature, 2016, 529 (7587): 484- 489.
doi: 10.1038/nature16961 |
| 66 |
SILVER D , SCHRITTWIESER J , SIMONYAN K , et al. Mastering the game of go without human knowledge[J]. Nature, 2017, 550 (7676): 354- 359.
doi: 10.1038/nature24270 |
| 67 | 曹雷. 基于深度强化学习的智能博弈对抗关键技术[J]. 指挥信息系统与技术, 2019, 10 (5): 1- 7. |
| CAO L . Key technologies of intelligent game confrontation based on deep reinforcement learning[J]. Command Information System and Technology, 2019, 10 (5): 1- 7. | |
| 68 | WANG Z , LI H , WU H L , et al. Improving maneuver strategy in air combat by alternate freeze games with a deep rein-forcement learning algorithm[J]. Mathematical Problems in Engineering, 2020, 2020 (22): 7180639. |
| 69 |
ZHANG G Y , LI Y , XU X H , et al. Efficient training techniques for multi-agent reinforcement learning in combat tasks[J]. IEEE Access, 2019, 7, 109301- 109310.
doi: 10.1109/ACCESS.2019.2933454 |
| 70 | BAI S X , SONG S M , LIANG S Y , et al. UAV maneuvering decision-making algorithm based on twin delayed deep deterministic policy gradient algorithm[J]. Journal of Artificial Intelligence and Technology, 2022, 2 (1): 16- 22. |
| 71 |
KONG W R , ZHOU D Y , YANG Z , et al. UAV autonomous aerial combat maneuver strategy generation with observation error based on state-adversarial deep deterministic policy gradient and inverse reinforcement learning[J]. Electronics, 2020, 9 (7): 1121- 1145.
doi: 10.3390/electronics9071121 |
| 72 | 况立群, 李思远, 冯利, 等. 深度强化学习算法在智能军事决策中的应用[J]. 计算机工程与应用, 2021, 57 (20): 271- 278. |
| KUANG L Q , LI S Y , FENG L , et al. Application of deep reinforcement learning algorithm on intelligent military decision system[J]. Computer Engineering and Applications, 2021, 57 (20): 271- 278. | |
| 73 | GHADERMAZI J, HORE S, SHARMA D, et al. Adversarial deep reinforcement learning enabled threat analytics framework for constrained spatio-temporal movement intelligence data[C]//Proc. of the IEEE International Conference on Intelligence and Security Informatics, 2021. |
| 74 | KALLSTROM J, HEINTZ F. Agent coordination in air combat simulation using multi-agent deep reinforcement learning[C]//Proc. of the IEEE International Conference on Systems, Man, and Cybernetics, 2020: 2157-2164. |
| 75 | FENG H F, ZENG W. Deep reinforcement learning for carrier-borne aircraft support operation scheduling[C]//Proc. of the International Conference on Intelligent Computing, Automation and Applications, 2021: 929-935. |
| 76 |
YANG Y , LI J T , PENG L L . Multi-robot path planning based on a deep reinforcement learning DQN algorithm[J]. CAAI Transactions on Intelligence Technology, 2020, 5 (3): 177- 183.
doi: 10.1049/trit.2020.0024 |
| 77 | LEI X Y , ZHANG Z A , DONG P F . Dynamic path planning of unknown environment based on deep reinforcement learning[J]. Journal of Robotics, 2018, (12): 1- 10. |
| 78 | YAN C , XIANG X J , WANG C . Towards real-time path planning through deep reinforcement learning for a UAV in dynamic environments[J]. Journal of Intelligent & Robotic Systems, 2020, 98 (2): 297- 309. |
| [1] | 李彦铃, 罗飞舟, 葛致磊. 基于鲁棒观测器的深度强化学习垂直起降运载器姿态稳定研究[J]. 系统工程与电子技术, 2024, 46(3): 1038-1047. |
| [2] | 吴冯国, 陶伟, 李辉, 张建伟, 郑成辰. 基于深度强化学习算法的无人机智能规避决策[J]. 系统工程与电子技术, 2023, 45(6): 1702-1711. |
| [3] | 唐进, 梁彦刚, 白志会, 黎克波. 基于DQN的旋翼无人机着陆控制算法[J]. 系统工程与电子技术, 2023, 45(5): 1451-1460. |
| [4] | 唐斯琪, 潘志松, 胡谷雨, 吴炀, 李云波. 深度强化学习在天基信息网络中的应用——现状与前景[J]. 系统工程与电子技术, 2023, 45(3): 886-901. |
| [5] | 李信, 李勇军, 赵尚弘. 基于深度强化学习的卫星光网络波长路由算法[J]. 系统工程与电子技术, 2023, 45(1): 264-270. |
| [6] | 王冠, 茹海忠, 张大力, 马广程, 夏红伟. 弹性高超声速飞行器智能控制系统设计[J]. 系统工程与电子技术, 2022, 44(7): 2276-2285. |
| [7] | 孟泠宇, 郭秉礼, 杨雯, 张欣伟, 赵柞青, 黄善国. 基于深度强化学习的网络路由优化方法[J]. 系统工程与电子技术, 2022, 44(7): 2311-2318. |
| [8] | 王玉佳, 方伟, 徐涛, 余应福, 邓博元. 基于遗传模糊树的海空对抗无人机智能决策模型[J]. 系统工程与电子技术, 2022, 44(12): 3756-3765. |
| [9] | 杨清清, 高盈盈, 郭玙, 夏博远, 杨克巍. 基于深度强化学习的海战场目标搜寻路径规划[J]. 系统工程与电子技术, 2022, 44(11): 3486-3495. |
| [10] | 高昂, 董志明, 李亮, 宋敬华, 段莉. MADDPG算法并行优先经验回放机制[J]. 系统工程与电子技术, 2021, 43(2): 420-433. |
| [11] | 马文, 李辉, 王壮, 黄志勇, 吴昭欣, 陈希亮. 基于深度随机博弈的近距空战机动决策[J]. 系统工程与电子技术, 2021, 43(2): 443-451. |
| [12] | 高昂, 郭齐胜, 董志明, 杨绍卿. 基于EAS+MADRL的多无人车体系效能评估方法研究[J]. 系统工程与电子技术, 2021, 43(12): 3643-3651. |
| [13] | 张堃, 李珂, 时昊天, 张振冲, 刘泽坤. 基于深度强化学习的UAV航路自主引导机动控制决策算法[J]. 系统工程与电子技术, 2020, 42(7): 1567-1574. |
| [14] | 降佳伟, 王宏艳, 吴彦鸿. 对地面动目标检测雷达的干扰技术综述[J]. 系统工程与电子技术, 2020, 42(11): 2471-2480. |
| [15] | 谢浩, 郭爱煌, 宋春林, 焦润泽. LTE-V下基于深度强化学习的基站选择算法[J]. 系统工程与电子技术, 2019, 41(7): 1652-1657. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||