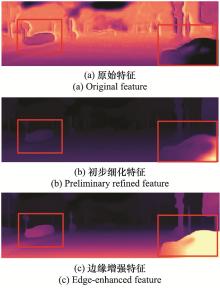
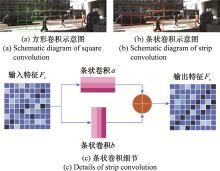
| 1 |
KIRAN B R , SOBH I , TALPAERT V , et al. Deep reinforcement learning for autonomous driving: a survey[J]. IEEE Trans.on Intelligent Transportation Systems, 2022, 23 (6): 4909- 4926.
doi: 10.1109/TITS.2021.3054625
|
| 2 |
ZENG A, SONG S, NIEBNER M, et al. 3D Match: learning local geometric descrip-tors from RGB-D reconstructions[C]//Proc. of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2017: 199-208.
|
| 3 |
MACARIO B A , MICHEL M , MOLINE Y , et al. A comprehensive survey of visual slam algorithms[J]. Robotics, 2022,
doi: 10.3350/robotics/1010024
|
| 4 |
陈科圻, 朱志亮, 邓小明, 等. 多尺度目标检测的深度学习研究综述[J]. 软件学报, 2021, 32 (4): 1201- 1227.
|
|
CHEN K Q , ZHU Z L , DENG X M , et al. A survey of deep learning research on multi-scale target detection[J]. Journal of Software, 2021, 32 (4): 1201- 1227.
|
| 5 |
曹自强, 赛斌, 吕欣. 行人跟踪算法及应用综述[J]. 物理学报, 2020, 69 (8): 41- 58.
|
|
CAO Z Q , SAI B , LYU X . A survey of pedestrian tracking algorithms and applications[J]. Acta Physica Sinica, 2020, 69 (8): 41- 58.
|
| 6 |
HOU L , LUO X Y , WANG Z Y , et al. Representation learning via a semi-supervised stacked distance autoencoder for image classification[J]. Frontiers of Information Technology & Electronic Engineering, 2020, 21 (7): 1005- 1019.
|
| 7 |
EIGEN D , PUHRSCH C , FERGUS R . Depth map prediction from a single image using a multi-scale deep network[J]. Advances in neural information processing systems, 2014, 27, 2366- 2374.
|
| 8 |
LAINA I, RUPPRECHT C, BELAGIANNIS V, et al. Deeper depth prediction with fully convolutional residual networks[C]//Proc. of the 4th IEEE Conference on International Conference on 3D Vision, 2016: 239-248.
|
| 9 |
FU H, GONG M M, WANG C H, et al. Deep ordinal regression network for monocular depth estimation[C]//Proc. of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018: 2002-2011.
|
| 10 |
YUAN W H, GU X D, DAI Z Z, et al. Neural window fully-connected CRFs for monocular depth estimation[C]//Proc. of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022: 3906-3915.
|
| 11 |
GODARD C, AODHA O M, BROSTOW G J. Unsupervised monocular depth estimation with left-right consistency[C]//Proc. of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2017: 270-279.
|
| 12 |
ZHOU T H, BROWN M, SNAVELY N, et al. Unsupervised learning of depth and ego-motion from video[C]//Proc. of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2017: 6612-6619.
|
| 13 |
GODARD C, AODHA O M, FIRMAN M, et al. Digging into self-supervised monocular depth estimation[C]//Proc. of the IEEE/CVF International Conference on Computer Vision, 2019: 3827-3837.
|
| 14 |
SHU C, YU K, DUAN Z X, et al. Feature-metric loss for self-supervised learning of depth and egomotion[C]//Proc. of European Conference on Computer Vision, 2020: 572-588.
|
| 15 |
LEE S, IM S, LIN S, et al. Learning monocular depth in dynamic scenes via instance aware projection consistency[C]//Proc. of the AAAI Conference on Artificial Intelligence, 2021, 1863-1872.
|
| 16 |
ZHU S J, BRAZIL G, LIU X M. The edge of depth: explicit constraints between segmentation and depth[C]//Proc. of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020: 13113-13122.
|
| 17 |
叶星余, 何元烈, 汝少楠. 基于生成式对抗网络及自注意力机制的无监督单目深度估计和视觉里程计[J]. 机器人, 2021, 43 (2): 203- 213.
|
|
YE X Y , HE Y L , RU S N . Unsupervised monocular depth estimation and visual odometer based on generative adversarial networks and self-attention mechanism[J]. Robot, 2021, 43 (2): 203- 213.
|
| 18 |
RONNEBERGER O, FISCHER P, BROX T. U-Net: convolutional networks for biomedical image segmentation[C]//Proc. of the International Conference on Medical Image Computing and Computer-assisted Intervention, 2015: 234-241.
|
| 19 |
XUE F , CAO J F , ZHOU Y , et al. Boundary-induced and scene-aggregated network for monocular depth prediction[J]. Pattern Recognition, 2021, 115, 107901.
doi: 10.1016/j.patcog.2021.107901
|
| 20 |
HOU B Q, ZHANG L, CHENG M M, et al. Strip pooling: rethinking spatial pooling for scene parsing[C]//Proc. of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020: 4003-4012.
|
| 21 |
HUANG G X, BORS A G. Busy-quiet video disentangling for video classification[C]//Proc. of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2022: 1341-1350.
|
| 22 |
WANG Z , BOVIK A C , SHEIKH H R , et al. Image quality assessment: from error visibility to structural similarity[J]. IEEE Trans.on Image Processing, 2004, 13 (4): 600- 612.
doi: 10.1109/TIP.2003.819861
|
| 23 |
GEIGER A , LENZ P , STILLER C , et al. Vision meets robotics: the KITTI dataset[J]. The International Journal of Robotics Research, 2013, 32 (11): 1231- 1237.
doi: 10.1177/0278364913491297
|
| 24 |
LI B , DAI Y C , HE M Y . Monocular depth estimation with hierarchical fusion of dilated CNNS and soft-weighted-sum inference[J]. Pattern Recognition, 2018, 83, 328- 339.
doi: 10.1016/j.patcog.2018.05.029
|
| 25 |
AKADA H, BHAT S F, ALHASHIM I, et al. Self-supervised learning of domain invariant features for depth estimation[C]//Proc. of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2022: 3377-3387.
|
| 26 |
ZHOU H, GREENWOOD D, TAYLOR S. Self-supervised monocular depth estimation with internal feature fusion[C]//Proc. of the 32nd British Machine Vision Conference, 2021: 378-391.
|
| 27 |
KLINGNER M, TERMOHLEN J A, MIKO-LAJCZYK J, et al. Self-supervised monocular depth estimation: solving the dynamic object problem by semantic guidance[C]//Proc. of European Conference on Computer Vision, 2020: 582-600.
|
| 28 |
CHOI J, JUNG D, LEE D, et al. SAFENet: self-supervised monocular depth estimation with semantic-aware feature extraction[EB/OL]. [2022-10-01] https://arxiv.org/abs/2010.02893.
|
| 29 |
LYU X Y, LIU L, WANG M M, et al. HR-depth: high resolution self-supervised monocular depth estimation[C]//Proc. of the AAAI Conference on Artificial Intelligence, 2021, 35(3): 2294-2301.
|
| 30 |
LIU H, ZHU Y, HUA G L, et al. Adaptive weighted network with edge enhancement module for monocular self-supervised depth estimation[C]//Proc. of ICASSP IEEE International Conference on Acoustics, Speech and Signal Processing, 2022: 2340-2344.
|
| 31 |
CHEN Z, YE X Q, YANG W, et al. Revealing the reciprocal relations between self supervised stereo and monocular depth estimation[C]//Proc. of the IEEE/CVF International Confe-rence on Computer Vision, 2021: 15529-15538.
|
| 32 |
BIAN J W , ZHAN H Y , WANG N Y , et al. Unsupervised scale-consistent depth learning from video[J]. International Journal of Computer Vision, 2021, 129 (9): 2548- 2564.
doi: 10.1007/s11263-021-01484-6
|
| 33 |
ZHANG S, ZHANG J, TAO D C. Towards scale-aware, robust, and generalizable unsupervised monocular depth estimation by integrating IMU motion dynamics[C]//Proc. of the European Conference on Computer Vision, 2022: 143-160.
|
| 34 |
KINGMA D P, BA J. Adam: a method for stochastic optimization[C]//Proc. of the International Conference on Learning Representations, 2015: 6980-6995.
|