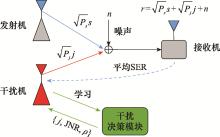
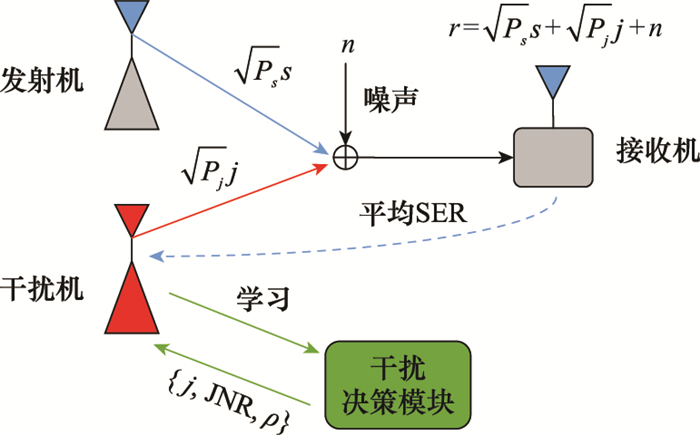
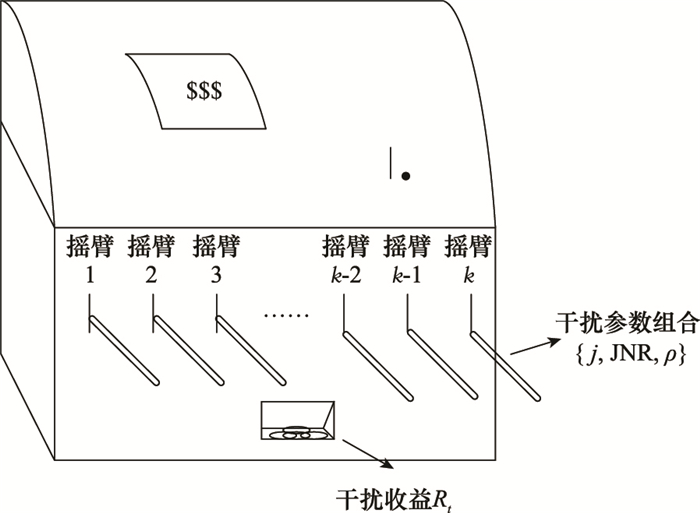
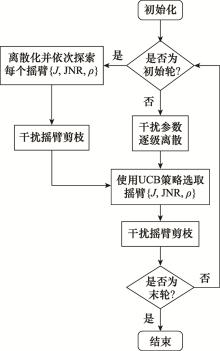
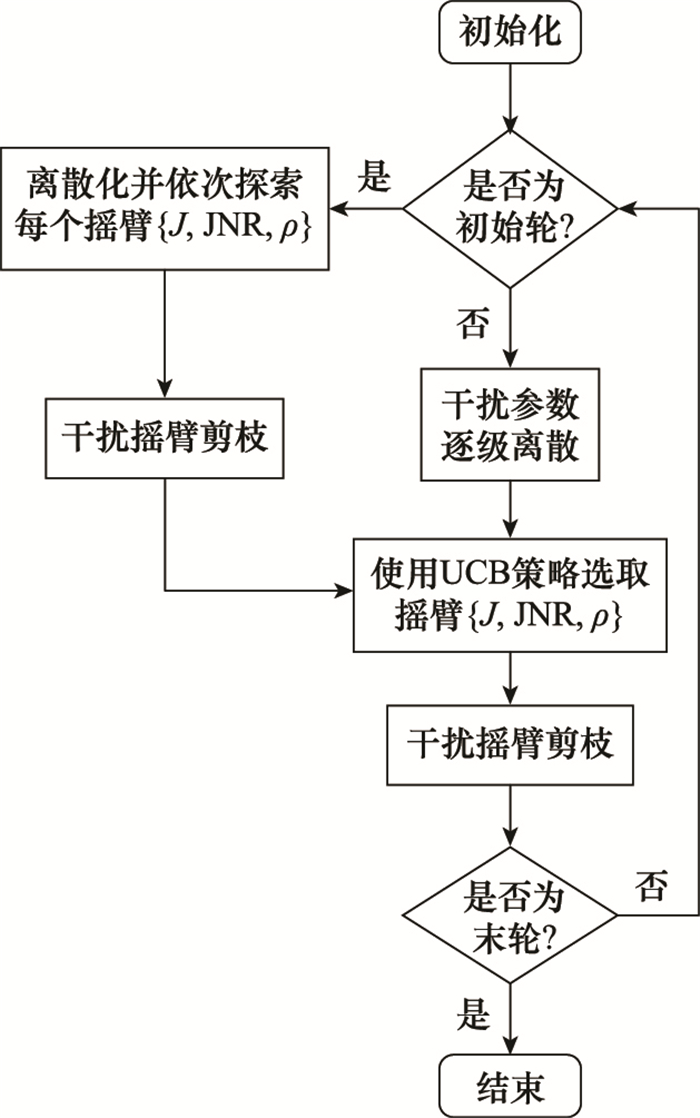
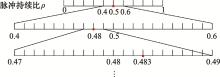
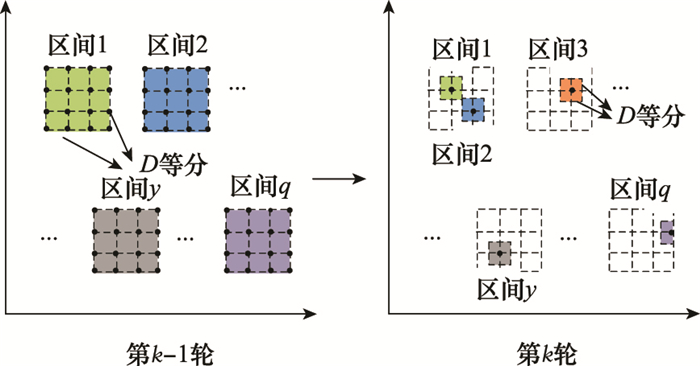
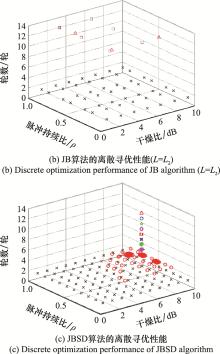
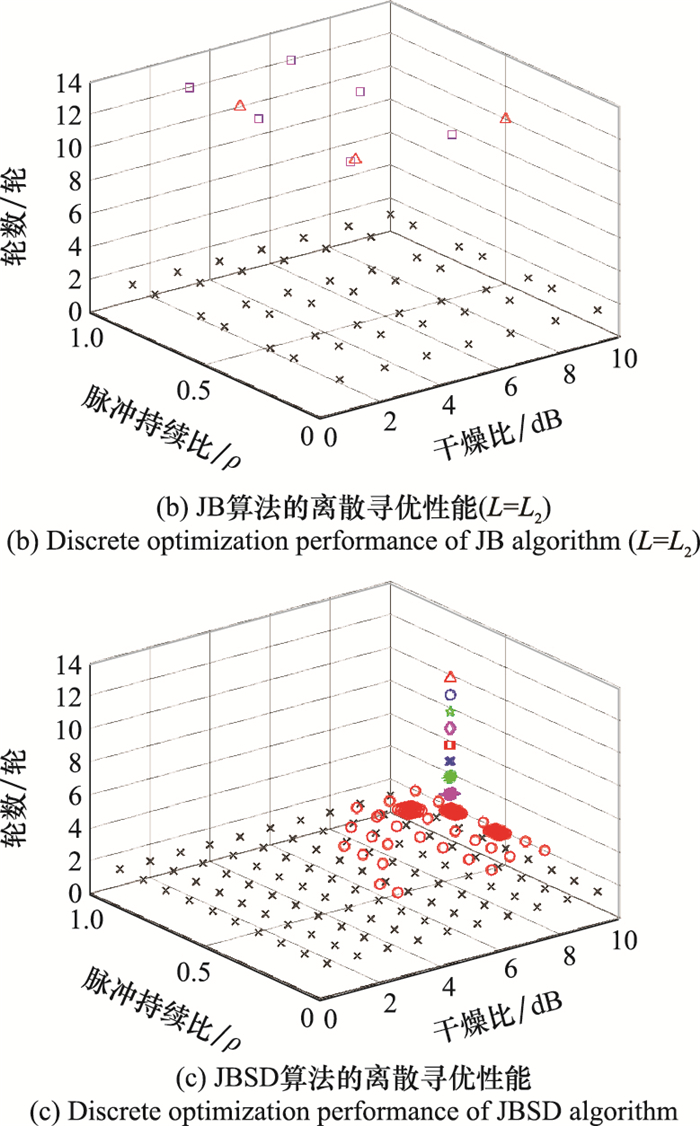
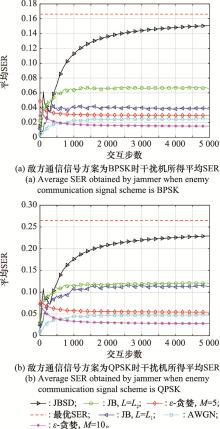
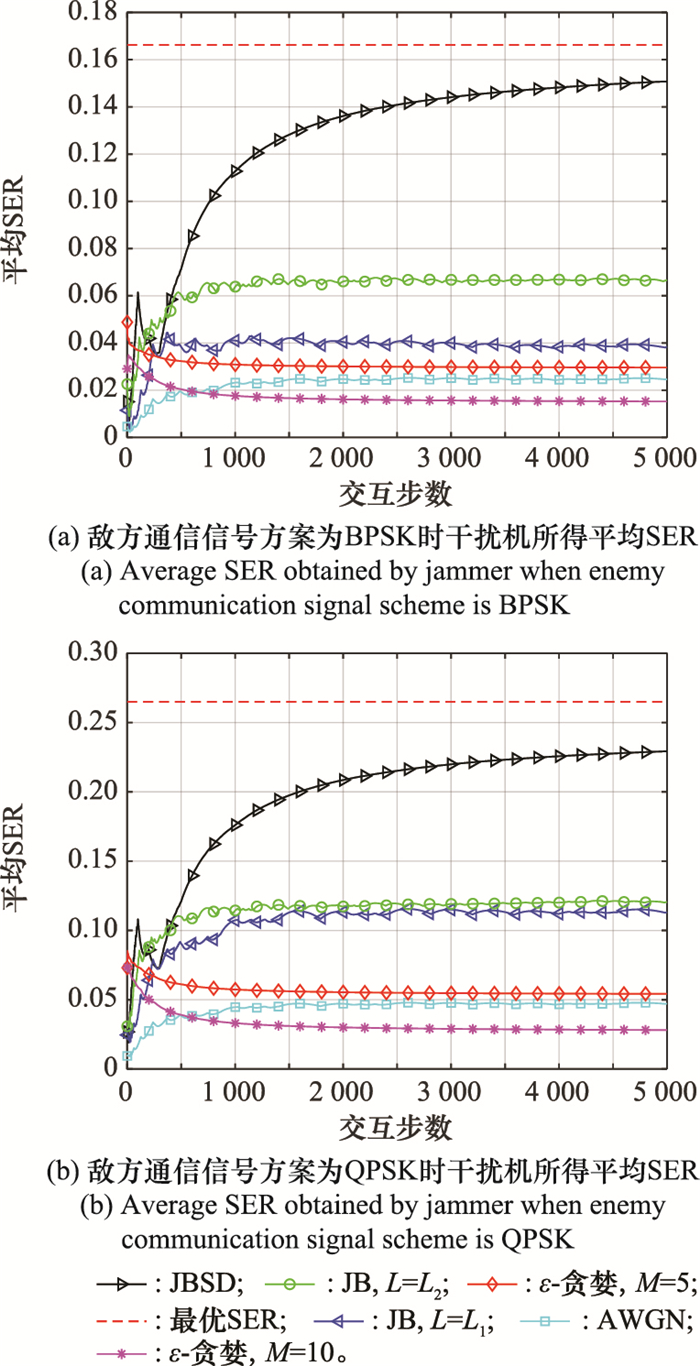
| 1 |
王沙飞, 鲍雁飞, 李岩. 认知电子战体系结构与技术[J]. 中国科学: 信息科学, 2018, 48 (12): 1603- 1613.
|
|
WANG S F , BAO Y F , LI Y . The architecture and technology of cognitive electronic warfare[J]. Scientia Sinica Informationis, 2018, 48 (12): 1603- 1613.
|
| 2 |
PAUL P , GHOSH S , BHATNAGAR M R . Abating jamming in free space optical systems-a game-theoretic solution[J]. IEEE Trans.on Communications, 2021, 69 (12): 8375- 8387.
doi: 10.1109/TCOMM.2021.3109941
|
| 3 |
LI Z M , CHEN X , ZHANG Y , et al. Fuzzy mathematics and game theory based D2D multicast network construction[J]. Journal of Systems Engineering and Electronics, 2019, 30 (1): 13- 21.
doi: 10.21629/JSEE.2019.01.02
|
| 4 |
LIU B , SU Z , XU Q C . Game theoretical secure wireless communication for UAV-assisted vehicular internet of things[J]. China Communications, 2021, 18 (7): 147- 157.
doi: 10.23919/JCC.2021.07.012
|
| 5 |
TAO H H , LIAO G S , YU J . Space-borne antenna adaptive anti-jamming method based on gradient-genetic algorithm[J]. Journal of Systems Engineering and Electronics, 2007, 18 (3): 469- 475.
doi: 10.1016/S1004-4132(07)60115-7
|
| 6 |
XIA J C, MA J, LI Y B, et al. Cooperative jamming resource allocation based on integer-encoded directed mutation artificial bee colony algorithm[C]//Proc. of the IEEE 4th International Conference on Electronic Information and Communication Technology, 2021: 695-700.
|
| 7 |
LIAO Y P, GUO W Y, HU L, et al. Application of improved genetic ant colony optimization in radar resource interference allocation[C]//Proc. of the IET International Radar Conference, 2020: 1728-1732.
|
| 8 |
AMURU S , BUEHRER R . Optimal jamming against digital modulation[J]. IEEE Trans.on Information Forensics & Security, 2015, 10 (10): 2212- 2224.
|
| 9 |
ISMAIL L, NIYATO D, SUN S M, et al. Jamming mitigation in JRC systems via deep reinforcement learning and backscatter-supported intelligent deception strategy[C]//Proc. of the IEEE 6th International Conference on Computer and Communication Systems, 2021: 1053-1058.
|
| 10 |
MOWLA N I , TRAN N H , DOH I , et al. AFRL: adaptive federated reinforcement learning for intelligent jamming defense in FANET[J]. Journal of Communications and Networks, 2020, 22 (3): 244- 258.
doi: 10.1109/JCN.2020.000015
|
| 11 |
WANG L L, PENG J L, XIE Z D, et al. Optimal jamming frequency selection for cognitive jammer based on reinforcement learning[C]//Proc. of the IEEE 2nd International Conference on Information Communication and Signal Processing, 2019: 39-43.
|
| 12 |
WANG F , ZHONG C , GURSOY M C , et al. Resilient dynamic channel access via robust deep reinforcement learning[J]. IEEE Access, 2021, 9, 163188- 163203.
doi: 10.1109/ACCESS.2021.3133506
|
| 13 |
WU W , YANG P , ZHANG W T , et al. Accuracy-guaranteed collaborative DNN inference in industrial IoT via deep reinforcement learning[J]. IEEE Trans.on Industrial Informatics, 2021, 17 (7): 4988- 4998.
doi: 10.1109/TII.2020.3017573
|
| 14 |
KIM G , LIM H . Reinforcement learning based beamforming jammer for unknown wireless networks[J]. IEEE Access, 2020, 8, 210127- 210139.
doi: 10.1109/ACCESS.2020.3039568
|
| 15 |
YANG H L, XIONG Z H, ZHAO J, et al. Intelligent reflecting surface assisted anti-jamming communications based on reinforcement learning[C]//Proc. of the IEEE Global Communications Conference, 2020.
|
| 16 |
WANG X M, CHEN X Q, WANG M, et al. Decentralized reinforcement learning based anti-jamming communication for self-organizing networks[C]//Proc. of the IEEE Wireless Communications and Networking Conference, 2021.
|
| 17 |
WANG W H , LYU Z F , LU X Z , et al. Distributed reinforcement learning based framework for energy-efficient UAV relay against jamming[J]. Intelligent and Converged Networks, 2021, 2 (2): 150- 162.
doi: 10.23919/ICN.2021.0010
|
| 18 |
LIU K X, LI P M, LIU C H, et al. UAV-aided anti-jamming maritime communications: a deep reinforcement learning approach[C]//Proc. of the 13th International Conference on Wireless Communications and Signal Processing, 2021.
|
| 19 |
YAO F Q , JIA L L . A collaborative multi-agent reinforcement learning anti-jamming algorithm in wireless networks[J]. IEEE Wireless Communications Letters, 2019, 8 (4): 1024- 1027.
doi: 10.1109/LWC.2019.2904486
|
| 20 |
XIAO L , LI Y D , DAI C H , et al. Reinforcement learning-based NOMA power allocation in the presence of smart jamming[J]. IEEE Trans.on Vehicular Technology, 2018, 67 (4): 3377- 3389.
doi: 10.1109/TVT.2017.2782726
|
| 21 |
SUTTON R , BARTO A . Reinforcement learning: an introduction[M]. 2018.
|
| 22 |
邢强, 贾鑫, 朱卫纲. 基于Q-学习的智能雷达对抗[J]. 系统工程与电子技术, 2018, 40 (5): 1031- 1035.
|
|
XING Q , JIA X , ZHU W G . Intelligent radar countermeasure based on Q-learning[J]. Systems Engineering and Electronics, 2018, 40 (5): 1031- 1035.
|
| 23 |
颛孙少帅, 杨俊安, 刘辉, 等. 基于正强化学习和正交分解的干扰策略选择算法[J]. 系统工程与电子技术, 2018, 40 (3): 518- 525.
|
|
ZHUANSUN S S , YANG J A , LIU H , et al. Jamming strategy learning based on positive reinforcement learning and ortho-gonal decomposition[J]. Systems Engineering and Electronics, 2018, 40 (3): 518- 525.
|
| 24 |
AMURU S , TEKIN C , SCHAAR M V D , et al. Jamming bandits-a novel learning method for optimal jamming[J]. IEEE Trans.on Wireless Communications, 2016, 15 (4): 2792- 2808.
doi: 10.1109/TWC.2015.2510643
|
| 25 |
AMURU S, BUEHRER R. Optimal jamming strategies in digi-tal communications-impact of modulation[C]//Proc. of the IEEE Global Communications Conference, 2014: 1619-1624.
|
| 26 |
PROAKIS J G , SALEHI M . Digital communications[M]. 2008.
|
| 27 |
AUER P . Finite-time analysis of the multiarmed bandit problem[J]. Machine Learning, 2002, 47, 235- 256.
doi: 10.1023/A:1013689704352
|
| 28 |
颛孙少帅. 基于强化学习理论的通信干扰策略学习方法研究[D]. 长沙: 国防科学技术大学, 2019.
|
|
ZHUANSUN S S. Research on reinforcement learning based communication jamming strategy learning methods[D]. Changsha: National University of Defense Technology, 2019.
|
| 29 |
ZHUANSUN S S, YANG J A, LIU H, et al. A novel jamming strategy-greedy bandit[C]//Proc. of the IEEE 9th International Conference on Communication Software and Networks, 2017: 1142-1146.
|
| 30 |
AUDIBERT J Y , MUNOS R , SZEPESVARI C . Exploration-exploitation tradeoff using variance estimates in multi-armed bandits[J]. Theoretical Computerence, 2009, 410 (19): 1876- 1902.
doi: 10.1016/j.tcs.2009.01.016
|