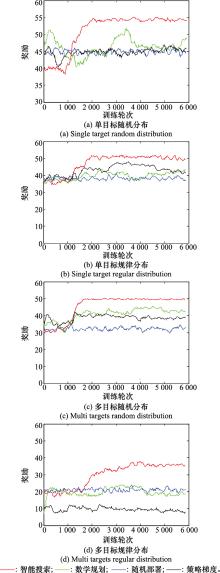
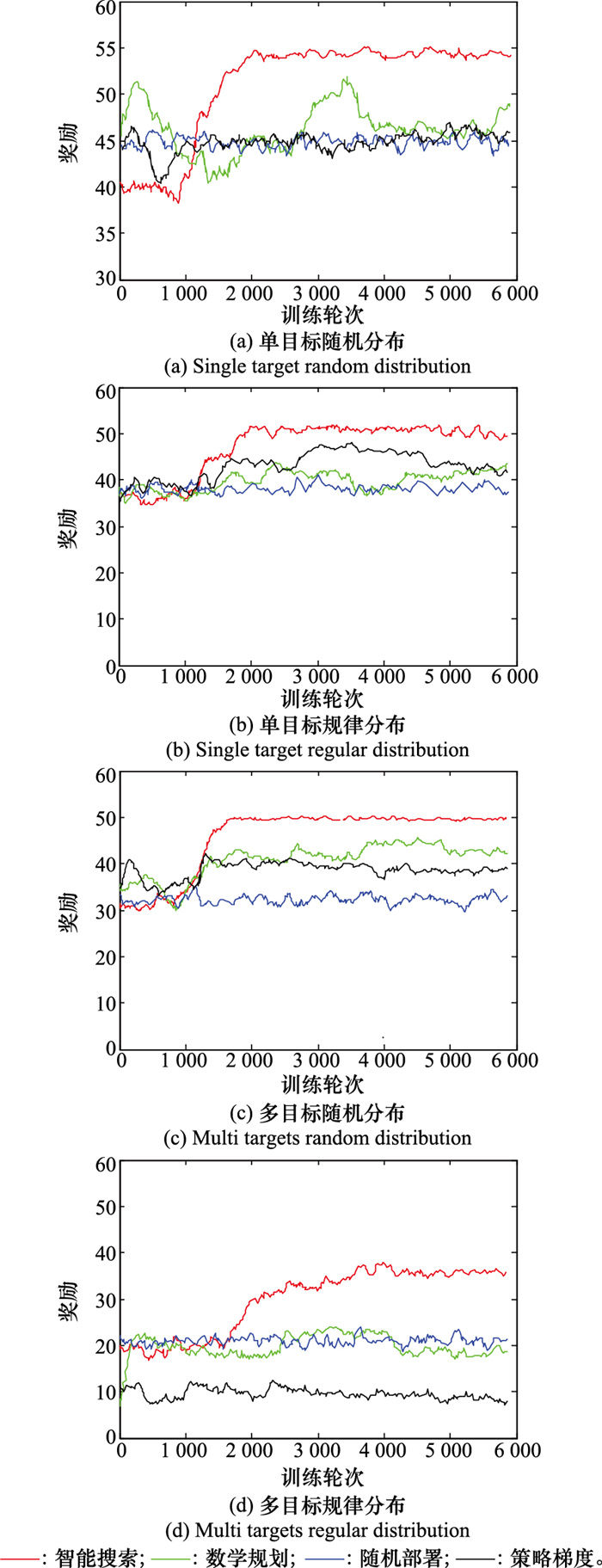
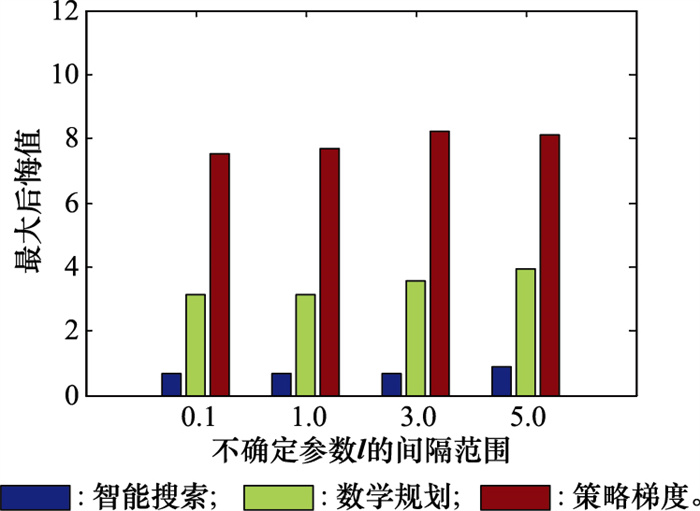
| 1 |
SANDS T . Development of deterministic artificial intelligence for unmanned underwater vehicles (UUV)[J]. Journal of Marine Science and Engineering, 2020, 8 (8): 578.
doi: 10.3390/jmse8080578
|
| 2 |
SMOLYANINOV I , BALZANO Q , YOUNG D . Development of broadband underwater radio communication for application in unmanned underwater vehicles[J]. Journal of Marine Science and Engineering, 2020, 8 (5): 370.
doi: 10.3390/jmse8050370
|
| 3 |
王淑敏, 唐晓聪. 无人潜航器的国际法法律地位研究-"中美无人潜航器事件"引发的思考[J]. 时代法学, 2017, 15 (4): 3- 8.
doi: 10.3969/j.issn.1672-769X.2017.04.001
|
|
WANG S M , TANG X C . Research on legal status of unmanned undersea vehicles in international law: reflections on the"unmanned undersea vehicles event between China and America"[J]. Presentday Law Science, 2017, 15 (4): 3- 8.
doi: 10.3969/j.issn.1672-769X.2017.04.001
|
| 4 |
刘丹. 无人潜航器的国际法规制-法律地位、现实挑战与我国的应对[J]. 中国海洋大学学报(社会科学版), 2021, 28 (3): 13- 27.
|
|
LIU D . The rule of international law regulating underwater unmanned vehicles: legal status, current challenges and solutions[J]. Journal of Ocean University of China (Social Sciences), 2021, 28 (3): 13- 27.
|
| 5 |
周华任, 王俐莉. 直升机反潜搜索博弈模型研究[J]. 军事运筹与系统工程, 2018, 32 (1): 27- 30.
doi: 10.3969/j.issn.1672-8211.2018.01.005
|
|
ZHOU H R , WANG L L . Game model of helicopter anti-submarine search[J]. Military Operations Research and Systems Engineering, 2018, 32 (1): 27- 30.
doi: 10.3969/j.issn.1672-8211.2018.01.005
|
| 6 |
潘磊, 潘宣宏. 反潜巡逻机与无人艇应召反潜中协同声纳搜潜研究[J]. 火力与指挥控制, 2021, 46 (8): 83- 88.
doi: 10.3969/j.issn.1002-0640.2021.08.014
|
|
PAN L , PAN X H . Research on cooperative use of sonar to search for the submarine with anti-submarine patrol aircraft and USV muster[J]. Fire Control & Command Control, 2021, 46 (8): 83- 88.
doi: 10.3969/j.issn.1002-0640.2021.08.014
|
| 7 |
MISHRA M , AN W , SIDOTI D , et al. Context-aware decision support for anti-submarine warfare mission planning within a dynamic environment[J]. IEEE Trans.on Systems, Man, and Cybernetics: Systems, 2017, 50 (1): 318- 335.
|
| 8 |
HEW P , YIAP N . Optimally randomized patrolling of chokepoints for theatre antisubmarine warfare[J]. Military Operations Research, 2018, 23 (1): 49- 56.
|
| 9 |
LAAN C M , BARROS A I , BOUCHERIE R J , et al. Optimal deployment for anti-submarine operations with time-dependent strategies[J]. The Journal of Defense Modeling and Simulation, 2020, 17 (4): 419- 434.
doi: 10.1177/1548512919855435
|
| 10 |
KIM R G. Operational planning for theater anti-submarine warfare[D]. Monterey: Naval Postgraduate School, 2017.
|
| 11 |
BALDESSARI A M. Navy operational planner: anti-submarine warfare with time-dependent performance[D]. Monterey: Naval Postgraduate School, 2017.
|
| 12 |
AZIZ R A , HE M L , ZHUANG J . An attacker-defender resource allocation game with substitution and complementary effects[J]. Risk Analysis, 2020, 40 (7): 1481- 1506.
doi: 10.1111/risa.13483
|
| 13 |
AN B , ORDONEZ F , TAMBE M , et al. A deployed quantal response-based patrol planning system for the US Coast Guard[J]. Interfaces, 2013, 43 (5): 400- 420.
doi: 10.1287/inte.2013.0700
|
| 14 |
CELLI A, CICCONE M, BONGO R, et al. Coordination in adversarial sequential team games via multi-agent deep reinforcement learning[EB/OL]. [2021-11-22]. https://arXiv.org/abs/1912.07712.
|
| 15 |
KAMRA N, GUPTA U, WANG K, et al. Deepfp for finding Nash equilibrium in continuous action spaces[C]//Proc. of the International Conference on Decision and Game Theory for Security, 2019: 238-258.
|
| 16 |
KAMRA N, GUPTA U, FANG F, et al. Policy learning for continuous space security games using neural networks[C]//Proc. of the 32nd AAAI Conference on Artificial Intelligence, 2018: 312-325.
|
| 17 |
ASHRAF S , SALEEM S , AHMED T . Sagacious communication link selection mechanism for underwater wireless sensors network[J]. Int. J. Wirel. Microw. Technol, 2020, 10 (4): 22- 33.
|
| 18 |
MUKAIDANI H , SARAVANAKUMAR R , XU H , et al. Stackelberg strategy for uncertain Markov jump delay stochastic systems[J]. IEEE Control Systems Letters, 2020, 4 (4): 1006- 1011.
doi: 10.1109/LCSYS.2020.2998430
|
| 19 |
CAÇADOR S , DIAS J M , GODINHO P . Global minimum variance portfolios under uncertainty: a robust optimization approach[J]. Journal of Global Optimization, 2020, 76 (2): 267- 293.
doi: 10.1007/s10898-019-00859-x
|
| 20 |
KNIGHT V , CAMPBELL J . Nashpy: a python library for the computation of Nash equilibria[J]. Journal of Open Source Software, 2018, 3 (30): 904.
doi: 10.21105/joss.00904
|
| 21 |
LI S H, WU Y, CUI X Y, et al. Robust multi-agent reinforcement learning via minimax deep deterministic policy gradient[C]//Proc. of the AAAI Conference on Artificial Intelligence, 2019, 33(1): 4213-4220.
|
| 22 |
ZHONG C , LU Z Y , GURSOY M C , et al. A deep actor-critic reinforcement learning framework for dynamic multichannel access[J]. IEEE Trans.on Cognitive Communications and Networking, 2019, 5 (4): 1125- 1139.
doi: 10.1109/TCCN.2019.2952909
|
| 23 |
YANG Y , LI J T , PENG L L . Multi-robot path planning based on a deep reinforcement learning DQN algorithm[J]. CAAI Transactions on Intelligence Technology, 2020, 5 (3): 177- 183.
doi: 10.1049/trit.2020.0024
|
| 24 |
COMPARE M , BARALDI P , MARELLI P , et al. Partially observable Markov decision processes for optimal operations of gas transmission networks[J]. Reliability Engineering & System Safety, 2020, 199 (6): 106- 120.
|
| 25 |
JIAO Z L, JAE O. End-to-end reinforcement learning for multi-agent continuous control[C]//Proc. of the 18th IEEE International Conference on Machine Learning and Applications, 2019: 535-540.
|
| 26 |
MAJUMDAR S, KHADKA S, MIRET S, et al. Evolutionary reinforcement learning for sample-efficient multiagent coordination[C]//Proc. of the International Conference on Machine Learning, 2020: 6651-6660.
|
| 27 |
PANG B , NIJKAMP E , WU Y N . Deep learning with tensorflow: a review[J]. Journal of Educational and Behavioral Statistics, 2020, 45 (2): 227- 248.
doi: 10.3102/1076998619872761
|
| 28 |
QIU S, WEI X H, YE J P, et al. Provably efficient fictitious play policy optimization for zero-sum markov games with structured transitions[C]//Proc. of the International Conference on Machine Learning, 2021: 8715-8725.
|
| 29 |
LIU S Q , CAO J J , WANG Y J , et al. Self-play reinforcement learning with comprehensive critic in computer games[J]. Neurocomputing, 2021, 449 (8): 207- 213.
|