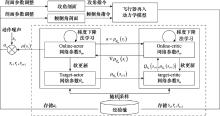
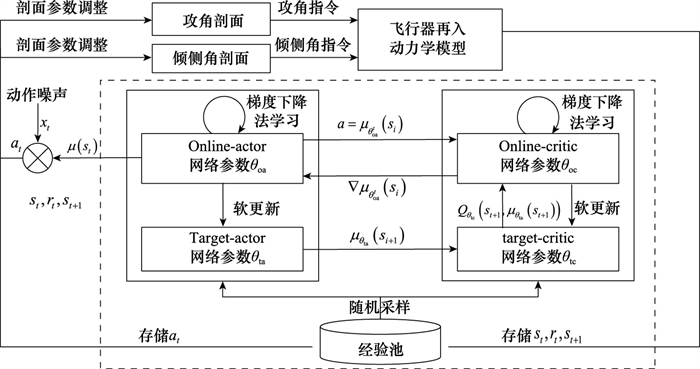
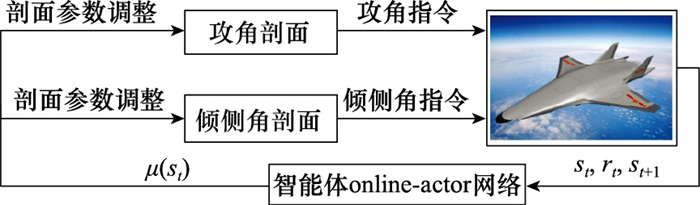
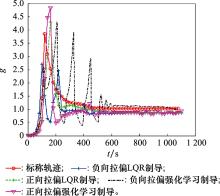
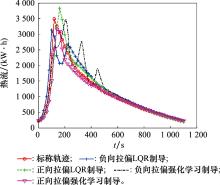
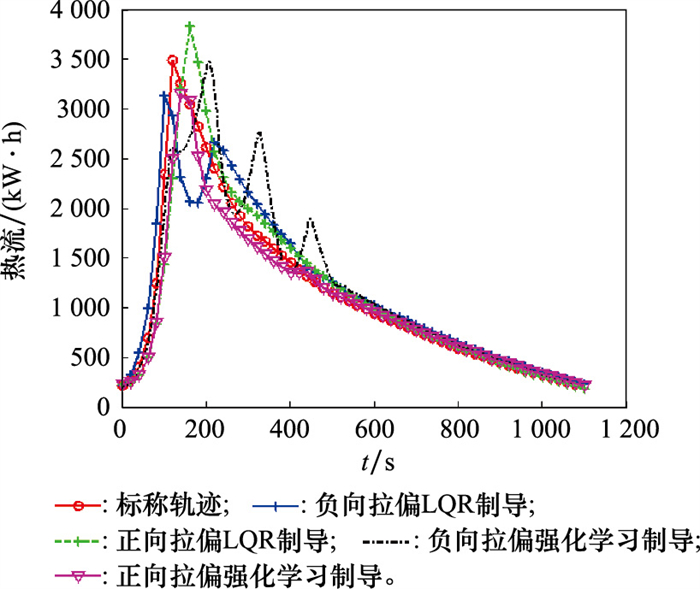
| 1 |
李凯文, 张涛, 王锐, 等. 基于深度强化学习的组合优化研究进展[J]. 自动化学报, 2020, 41 (11): 2521- 2537.
|
|
LI K W , ZHANG T , WANG R , et al. Research reviews of combinatorial optimization methods based on deep reinforcement learning[J]. Acta Automatica Sinica, 2020, 41 (11): 2521- 2537.
|
| 2 |
ZHANG H P , WANG H L , LI N , et al. Time-optimal memetic whale optimization algorithm for hypersonic vehicle reentry tra-jectory optimization with no-fly zones[J]. Neural Computing and Applications, 2020, 32 (7): 2735- 2749.
doi: 10.1007/s00521-018-3764-y
|
| 3 |
高嘉时. 升力式再入飞行器轨迹优化与制导方法研究[D]. 武汉: 华中科技大学, 2019.
|
|
GAO J S. Research on trajectory optimization and guidance method of lift reentry vehicle[D]. Wuhan: Huazhong University of Science and Technology, 2019.
|
| 4 |
LI R F , HU L , CAI L . Adaptive tracking control of a hypersonic flight aircraft using neural networks with reinforcement syn-thesis[J]. Aero Weaponry, 2018, (6): 3- 10.
|
| 5 |
杨烨峰, 邓凯, 左英琦, 等. PILCO框架对飞行姿态模拟器系统的参数设计与优化[J]. 光学精密工程, 2019, 27 (11): 2365- 2373.
|
|
YANG Y F , DENG K , ZUO Y Q , et al. Parameter design and optimization of flight attitude simulator system based on pilco framework[J]. Optical Precision Engineering, 2019, 27 (11): 2365- 2373.
|
| 6 |
甄岩, 郝明瑞. 基于深度强化学习的智能PID控制方法研究[J]. 战术导弹技术, 2019, (5): 37- 43.
|
|
ZHEN Y , HAO M R . Research on Intelligent PID control method based on deep reinforcement learning[J]. Tactical Missile Technology, 2019, (5): 37- 43.
|
| 7 |
任坚, 刘剑慰, 杨蒲. 基于增量式策略强化学习算法的飞行控制系统的容错跟踪控制[J]. 控制理论与应用, 2020, 37 (7): 1429- 1438.
|
|
REN J , LIU J W , YANG P . Fault tolerant tracking control of flight control system based on incremental strategy reinforcement learning algorithm[J]. Control theory and application, 2020, 37 (7): 1429- 1438.
|
| 8 |
KOCH W , MANCUSO R , WEST R , et al. Reinforcement learning for UAV attitude control[J]. ACM Transactions on Cyber-Physical Systems, 2019, 3 (2): 1- 21.
|
| 9 |
LAMBERT N O , SCHINDLER C B , DREW D S , et al. Nonholonomic yaw control of an underactuated flying robot with model-based reinforcement learning[J]. IEEE Robotics and Automation Letters, 2020, 6 (2): 455- 461.
|
| 10 |
TANG C, LAI Y C. Deep reinforcement learning automatic landing control of fixed-wing aircraft using deep deterministic policy gradient[C]//Proc. of the IEEE International Confe-rence on Unmanned Aircraft Systems, 2020.
|
| 11 |
CHENG Y, SHUI Z S, XU C, et al. Cross-cycle iterative unmanned aerial vehicle reentry guidance based on reinforcement learning[C]//Proc. of the IEEE International Conference on Unmanned Systems, 2019: 587-592.
|
| 12 |
涂铮铮. 基于进化和强化学习算法的动态路径规划研究[D]. 成都: 电子科技大学, 2020.
|
|
TU Z Z. Research on dynamic path planning based on evolution and reinforcement learning algorithm[D]. Chengdu: University of Electronic Science and Technology of China, 2020.
|
| 13 |
邱月, 郑柏通, 蔡超. 多约束复杂环境下UAV航迹规划策略自学习方法[J]. 计算机工程, 2021, 47 (5): 44- 51.
|
|
QIU Y , ZHENG B T , CAI C . Self learning method of UAV path planning strategy in complex environment with multiple constraints[J]. Computer Engineering, 2021, 47 (5): 44- 51.
|
| 14 |
GAUDET B , FURFARO R , LINARES R . Reinforcement learning for angle-only intercept guidance of maneuvering targets[J]. Aerospace Science and Technology, 2020, 99 (4): 105746.
|
| 15 |
LU P . Entry guidance: a unified method[J]. Journal of Gui-dance, Control, and Dynamics, 2014, 37 (3): 713- 728.
doi: 10.2514/1.62605
|
| 16 |
崔乃刚, 李浩, 卢宝刚, 等. 可重复使用飞行器制导控制一体化技术[J]. 光学精密工程, 2017, 25 (12): 52- 58.
|
|
CUI N G , LI H , LU B G , et al. Integrated guidance and control for reusable launch vehicle[J]. Optics and Precision Engineering, 2017, 25 (12): 52- 58.
|
| 17 |
SHEN Z J , LU P . Onboard generation of three-dimensional constrained entry trajectories[J]. Journal of Guidance, control, and Dynamics, 2003, 26 (1): 111- 121.
doi: 10.2514/2.5021
|
| 18 |
ZHAO J , ZHOU R , JIN X L . Progress in reentry trajectory planning for hypersonic vehicle[J]. Journal of Systems Engineering and Electronics, 2014, 25 (4): 627- 639.
doi: 10.1109/JSEE.2014.00073
|
| 19 |
ARULKUMARAN K , DEISENROTH M P , BRUNDAGE M , et al. Deep reinforcement learning: a brief survey[J]. IEEE Signal Processing Magazine, 2017, 34 (6): 26- 38.
doi: 10.1109/MSP.2017.2743240
|
| 20 |
LILLICRAP T P, HUNT J J, PRITZEL A, et al. Continuous control with deep reinforcement learning[EB/OL]. [2021-06-02]. https://axiv.org/abs/1509.02971.
|
| 21 |
GAO J S, SHI X M, CHENG Z T, et al. Reentry trajectory optimization based on deep reinforcement learning[C]//Proc. of the IEEE Chinese Control and Decision Conference, 2019: 2588-2592.
|
| 22 |
KE H C , WANG J , DENG L Y , et al. Deep reinforcement learning-based adaptive computation offloading for MEC in hete-rogeneous vehicular networks[J]. IEEE Trans.on Vehicular Technology, 2020, 69 (7): 7916- 7929.
doi: 10.1109/TVT.2020.2993849
|
| 23 |
NAUTA J, KHALUF Y, SIMOENS P. Using the Ornstein-Uhlenbeck process for random exploration[C]//Proc. of the 4th International Conference on Complexity, Future Information Systems and Risk, 2019.
|
| 24 |
党选举, 王凯利, 姜辉, 等. 工业机器人谐波减速器迟滞特性的神经网络建模[J]. 光学精密工程, 2019, 27 (3): 694- 701.
|
|
DANG X J , WANG K L , JIANG H , et al. Neural network mode-ling of hysteresis for harmonic drive in industrial robots[J]. Optics and Precision Engineering, 2019, 27 (3): 694- 701.
|