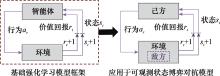
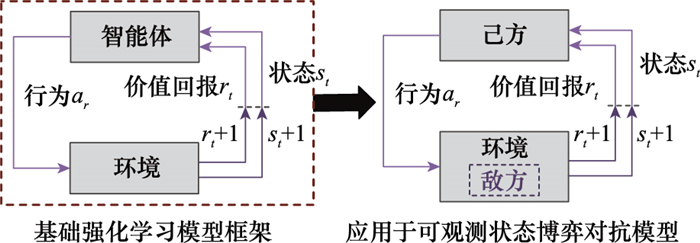
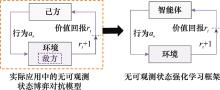
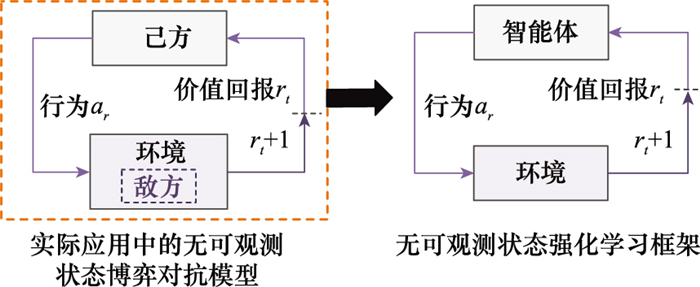
| 1 |
YAN C , XIANG X J , WANG C . Towards real-time path planning through deep reinforcement learning for a UAV in dynamic environments[J]. Journal of Intelligent & Robotic Systems, 2020, 98 (2): 297- 309.
|
| 2 |
PENG H X , SHEN X M . Multi-agent reinforcement learning based resource management in MEC-and UAV-assisted vehicular networks[J]. IEEE Journal on Selected Areas in Communications, 2020, 39 (1): 131- 141.
|
| 3 |
XIAO Z Y , ZHU L P , LIU Y M , et al. A survey on millimeter-wave beamforming enabled UAV communications and network-ing[J]. IEEE Communications Surveys & Tutorials, 2021, 24 (1): 557- 610.
|
| 4 |
HE L , AOUF N , SONG B F . Explainable deep reinforcement learning for UAV autonomous path planning[J]. Aerospace Science and Technology, 2021, 118, 107052.
doi: 10.1016/j.ast.2021.107052
|
| 5 |
NEMER I A , SHELTAMI T R , BELHAIZA S , et al. Energy-efficient UAV movement control for fair communication coverage: a deep reinforcement learning approach[J]. Sensors, 2022, 22 (5): 1919.
doi: 10.3390/s22051919
|
| 6 |
KHOROSHKO V , HRYSHCHUK R , BRAILOVSKYI N , et al. The use of game theory to study processes in the informational confrontation[J]. Scientific and Practical Cyber Security Journal, 2020, 4 (3): 45- 51.
|
| 7 |
ZHANG Q X , WEN H , LIU Y , et al. Federated reinforcement learning enabled joint communication, sensing and computing resources allocation in connected automated vehicles networks[J]. IEEE Internet of Things Journal, 2022, 9 (22): 23224- 23240.
doi: 10.1109/JIOT.2022.3188434
|
| 8 |
AREF M A, JAYAWEERA S K. Spectrum-agile cognitive interference avoidance through deep reinforcement learning[C]//Proc. of the International Conference on Cognitive Radio Oriented Wireless Networks, 2019: 218-231.
|
| 9 |
LIU H D , ZHANG H T , HE Y , et al. Jamming strategy optimization through dual Q-learning model against adaptive radar[J]. Sensors, 2021, 22 (1): 145.
doi: 10.3390/s22010145
|
| 10 |
SMITH G E, REININGER T J. Reinforcement learning for waveform design[C]//Proc. of the IEEE Radar Conference, 2021.
|
| 11 |
ABEDIN S F , MUNIR M S , TRAN N H , et al. Data fresh-ness and energy-efficient UAV navigation optimi-zation: a deep reinforcement learning approach[J]. IEEE Trans.on Intelligent Transportation Systems, 2020, 22 (9): 5994- 6006.
|
| 12 |
LEVIN E, PIERACCINI R, ECKERT W. Using Markov decision process for learning dialogue strategies[C]//Proc. of the IEEE International Conference on Acoustics, Speech and Signal Processing, 1998: 201-204.
|
| 13 |
VAN O M, WIERING M. Reinforcement learning and Markov decision processes[M]//MARCO W, MARTIJN O. Reinforcement Learning. Heidelberg: Springer, 2012: 3-42.
|
| 14 |
SHAMSHIRBAND S , PATEL A , ANUAR N B , et al. Cooperative game theoretic approach using fuzzy Q-learning for detecting and preventing intrusions in wireless sensor networks[J]. Engineering Applications of Artificial Intelligence, 2014, 32, 228- 241.
doi: 10.1016/j.engappai.2014.02.001
|
| 15 |
WATKINS C , DAYAN P . Technical note: Q-learning[J]. Machine Learning, 1992, 8 (3): 279- 292.
|
| 16 |
MNIH V , KAVUKCUOGLU K , SILVER D , et al. Human-level control through deep reinforcement learning[J]. Nature, 2015, 518 (7540): 529- 533.
doi: 10.1038/nature14236
|
| 17 |
SILVER D , HUANG A , MADDISON C J , et al. Mastering the game of Go with deep neural networks and tree search[J]. Nature, 2016, 529 (7587): 484.
doi: 10.1038/nature16961
|
| 18 |
LI Y Y , WANG X M , LIU D X , et al. On the performance of deep reinforcement learning-based anti-jamming method confronting intelligent jammer[J]. Applied Sciences, 2019, 9 (7): 1361- 1376.
doi: 10.3390/app9071361
|
| 19 |
AREF M A, JAYAWEERA S K. Spectrum-agile cognitive interference avoidance through deep reinforcement learning[C]//Proc. of the International Conference on Cognitive Radio Oriented Wireless Networks, 2019: 218-231.
|
| 20 |
VAN H H, GUEZ A, SILVER D. Deep reinforcement learning with double Q-learning[EB/OL]. [2021-08-25]. https://arxiv.org/abs/1509.06461.
|
| 21 |
KONG W R , ZHOU D Y , YANG Z , et al. UAV autonomous aerial combat maneuver strategy generation with observation error based on state-adversarial deep deterministic policy gradient and inverse reinforcement learning[J]. Electronics, 2020, 9 (7): 1121- 1145.
doi: 10.3390/electronics9071121
|
| 22 |
DEGRIS T, WHITE M, SUTTON R S. Off-policy actor-critic[EB/OL]. [2021-08-25]. https://arxiv.org/abs/1205.4839v3.
|
| 23 |
LILLICRAP T, HUNT J J, PRITZEL A, et al. Continuous control with deep reinforcement learning[C]//Proc. of the International Conference on Learning Representations, 2016.
|
| 24 |
LI K , JIU B , WANG P H , et al. Radar active antagonism through deep reinforcement learning: a way to address the challenge of mainlobe jamming[J]. Signal Processing, 2021, 186, 108130.
doi: 10.1016/j.sigpro.2021.108130
|
| 25 |
LEE J , NIYATO D , GUAN Y L , et al. Learning to schedule joint radar-communication with deep multi-agent reinforcement learning[J]. IEEE Trans.on Vehicular Technology, 2021, 71 (1): 406- 422.
|
| 26 |
STEPHAN M , SERVADEI L , ARJONA-MEDINA J , et al. Scene-adaptive radar tracking with deep reinforcement learning[J]. Machine Learning with Applications, 2022, 8, 100284.
|
| 27 |
WANG S S , LIU Z , XIE R , et al. Reinforcement learning for compressed-sensing based frequency agile radar in the presence of active interference[J]. Remote Sensing, 2022, 14 (4): 968- 988.
|
| 28 |
MENG F Q , TIAN K S , WU C F . Deep reinforcement learning-based radar network target assignment[J]. IEEE Sensors Journal, 2021, 21 (14): 16315- 16327.
|
| 29 |
ALPDEMIR M N . Tactical UAV path optimization under radar threat using deep reinforcement learning[J]. Neural Computing and Applications, 2022, 34 (7): 5649- 5664.
doi: 10.1007/s00521-021-06702-3?utm_source=xmol&utm_content=meta
|
| 30 |
STEVENS T S W, TIGREK R F, TAMMAM E S, et al. Automated gain control through deep reinforcement learning for downstream radar object detection[C]//Proc. of the 29th European Signal Processing Conference, 2021: 1780-1784.
|
| 31 |
CHEN P Z , LU W Q . Deep reinforcement learning based moving object grasping[J]. Information Sciences, 2021, 565, 62- 76.
|